背景
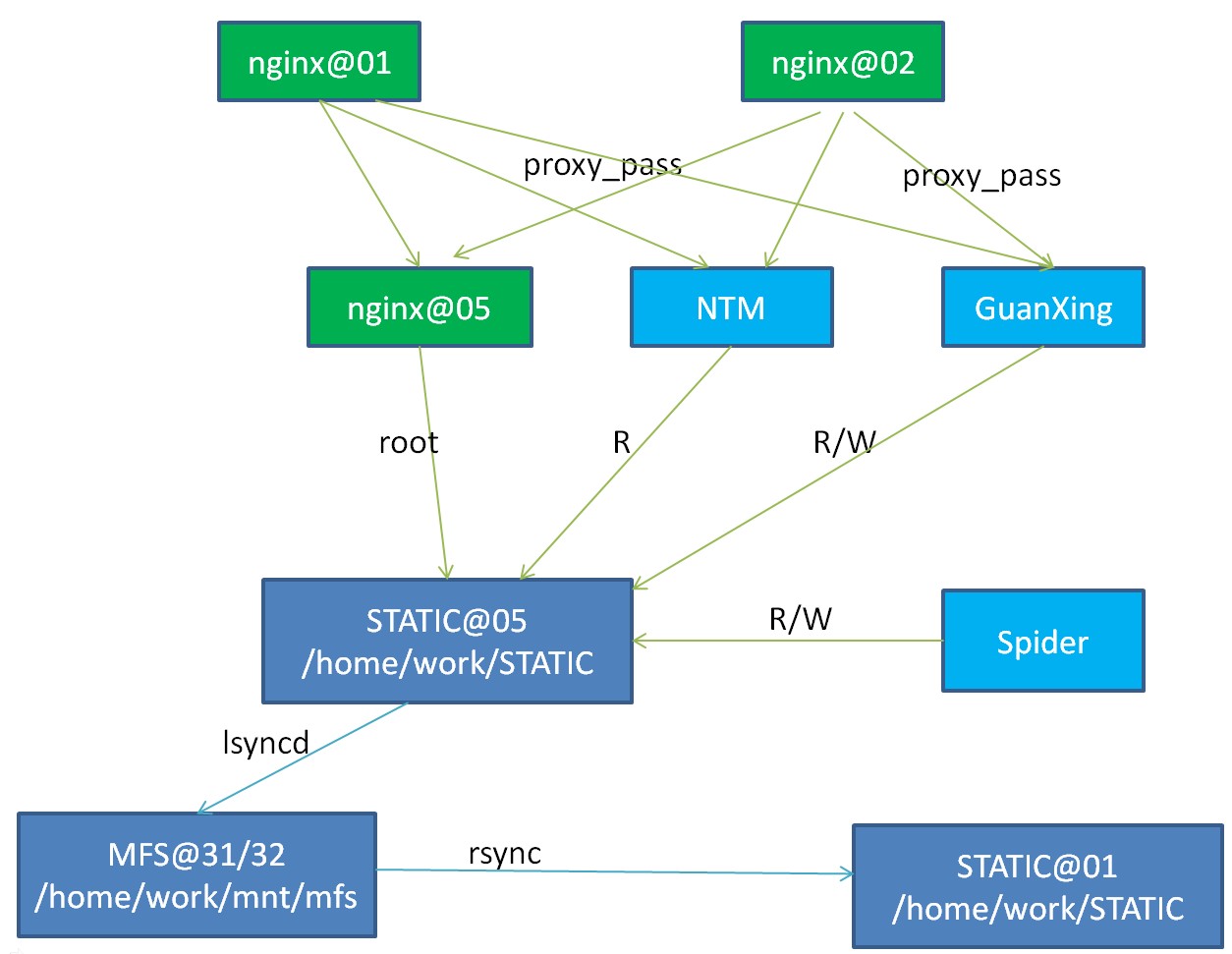
目前的静态资源以普通Linux文件系统(Ext3)的方式存放在05机器上,主要是图片和新闻(以及新闻附带的图片)。每半个小时更新一次。通过rsync + cron 脚本定时同步到01。01只是备份,不提供服务。随着静态资源的增加,静态服务器的压力比较大,而且读写服务是单点,虽然有冗余容灾,但是不能同时提供服务,不具有线性拓展性。一般来说海量的文件系统都需要使用分布式文件系统。具体参见海量图片存储思考。
目前的文件数量有1000w左右,基本都是图片和HTML文件。
关于MFS
MFS是Moose File System的简称,与我们熟悉的fat,ntfs,ext3一样是一种文件系统(驼鹿文件系统)。与普通的文件系统不同,MFS是一种分布式的文件系统,类似的分布式的文件系统还有NFS,Hadoop,HDFS,Lustre,GFS等。准确的来说,MFS是对Google的GFS的开源实现。MFS因其高可靠、动态扩展、灾难冗余等诸多优秀特性,当然最重要是因为MFS是开源的,被广泛的应用于海量文件分布式存贮等场景中。
MFS的特性主要有以下几点:
- MFS是通用的文件系统,不需要修改上层应用就可以使用。MFS中的所有基本操作和普通的文件系统中的操作无任何差异,你可以直接cp,mv,rm,ls,无需特殊指令。
- MFS支持在线扩容,体系架构的动态可扩展性极强。也就是说可以在任何时刻增加或减少MFS集群中的存储机器,而对MFS集群的整体运作部产生任何影响。
- MFS具有高容错性,不存在单点故障。在MFS中,单一机器(准确的说是存储机器)的故障被认为是常态事件。MFS对单一机器的故障无感,前提是文件设置了多个副本。
- MFS提供垃圾回收机制。被删除的文件不会立刻从MFS系统中消失,而是被存放在回收站中,超过了回收时间之后才会真正被删除,这样可以有效防止误操作。
- MFS是Google File System的一个C的开源实现。MFS的理论依据是“The Google File System”这篇论文,有谷歌提供的强大理论依据。同时,MFS是开源的,有专门的开发团队进行开发维护。
除了上述的这些特性之外,MFS还提供了文件备份份数设置,文件快照Snapshot等功能,针对随机读或写和海量小文件的读写也有一定的优化。
迁移MFS方案
步骤
- 搭建MFS和mount MFS(/home/work/mnt/mfs)
- 编写同步脚本,同步 STATIC ==> MFS
- 保险起见,停止静态资源写服务(Spider和Guanxing)
- 修改同步脚本,将同步方向变为 MFS ==> STATIC(因为已经停止了写服务,两边应该是对等的,可以忽略startup rsync,直接使用inotify增量同步)
- 修改服务访问MFS目录(/home/work/mnt/mfs)
- 切换读服务: nginx, NTM(其实都走CDN和nginx了)
- 切换写服务:Guanxing、Spider(基本是修改配置文件,需要发布和重启应用)
- 验证服务
故障回滚方案
为了防止MFS故障导致应用不可用,这里做了一些措施方便回滚。
1. 使用inotify机制实现准实时备份
迁移MFS之后,我们会同时将MFS文件同步回老的STATIC目录。为了保证实时性和性能,使用inotify事件监听处理机制,具体参见如何实时同步大量小文件。
settings {
statusFile = "/tmp/lsyncd.stat",
logfile = "/tmp/lsyncd.log",
logfacility = daemon,
statusIntervall = 20,
maxDelays = 10,
maxProcesses = 4
}
sync {
default.direct,
source="/home/work/STATIC",
target="/home/work/mnt/mfs"
}
说明:由于startup rsync太耗时,所以在停止写服务器的情况下,可以用sync{..., init = false}略过。
2. nginx动静分离避免静态资源故障拖垮所有接口
为了避免静态资源出现问题,导致整个nginx都不可用,影响所有接口。我们把所有的静态资源请求统一转发给05的nginx处理。01和02的nginx主要负责转发动态请求给tomcat和静态请求给nginx@05。
并且为了避免后端静态服务nginx故障导致卡住太久,对入口nginx转发后端静态资源nginx的响应时间设置了比较短的超时时间。这个主要是通过三个超时参数控制的:
- proxy_connect_timeout
- Syntax: proxy_connect_timeout time;
- Default: proxy_connect_timeout 60s;
- Context: http, server, location
- Defines a timeout for establishing a connection with a proxied server. It should be noted that this timeout cannot usually exceed 75 seconds.
- proxy_read_timeout
- Syntax: proxy_read_timeout time;
- Default: proxy_read_timeout 60s;
- Context: http, server, location
- Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
- proxy_send_timeout
- Syntax: proxy_send_timeout time;
- Default: proxy_send_timeout 60s;
- Context: http, server, location
- Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
默认的60s超时时间有点太长了,对于卡住的情况来说容易出现拖垮入口nginx的情况,所以结合业务情况做了如下配置:
proxy_connect_timeout 5;
proxy_read_timeout 10;
proxy_send_timeout 5;
然后设置了允许的最大错误次数。如果静态资源出现问题,那么当05返回的错误次数超过max_failed,01和02的nginx就会将05摘除。也就是01和02还能提供动态请求:
upstream static-mbrowser { server hk01-hao123-mob05.hk01:10000 max_fails=2 fail_timeout=30s; # MFS
}
TIPS If you use only one upstream server, the max_fails & fail_timeout parameter are ignored. 所以要达到自动摘除不可用backend服务,至少需要配置两个backend server。我们下面刚好会配置这么一个backup Server。
3. 老的STATIC静态资源作为备份服务
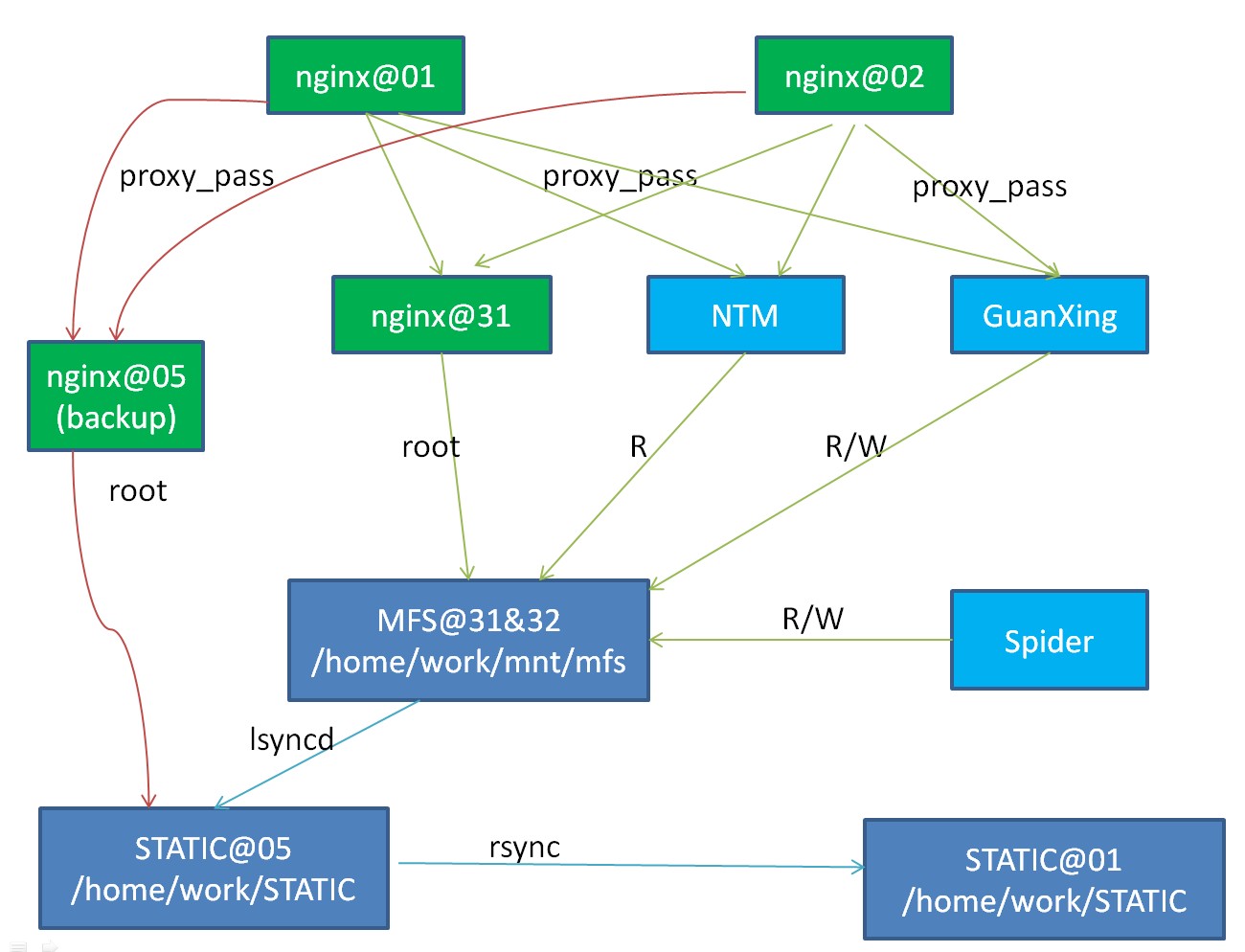
经过前面的两个步骤,MFS就算出问题,顶多也就是静态资源不可用,NTM的接口层动态请求并不会受到影响。但是更进一步的,还能够让MFS也有读备份。就是搭建05的nginx备份,也是提供静态资源服务,但是这个nginx指向的是老的STATIC目录。也就是说老的静态资源服务也通过nginx提供服务了。
upstream static-mbrowser { server hk01-hao123-mob05.hk01:10000 max_fails=2 fail_timeout=30s; # MFS
server hk01-hao123-mob31.hk01:10000; # old STATIC
}
但是这种情况下,老的STATIC目录也提供服务了。虽然有inotify作为增量同步,但是也不能保证百分百实时。所以我们希望老的STATIC目录只有当MFS出现问题的时候才做为备份提供服务。查看了一下nginx的文档,果然有这个配置项upstream - backup:
backup marks the server as a backup server. It will be passed requests when the primary servers are unavailable.
于是只需要简单增加一个配置项:
upstream static-mbrowser { server hk01-hao123-mob05.hk01:10000 max_fails=2 fail_timeout=30s; # MFS
server hk01-hao123-mob31.hk01:10000 backup; # old STATIC
}
这样,假设MFS真的挂了,那么读请求通过nginx在失败2次之后,会在30s内将请求都转移到老的STATIC服务器。这样,我们把MFS故障的影响范围和影响时间都大大的缩小在可控的范围内。 当然这里有两个地方需要注意一下:
- 老的STATIC服务器需要相对够实时,否则新的静态资源会请求不到。这个经过测试和观察,只要inotify运行着,同步是非常实时的。为了避免同步脚本被killed,还写了个cron脚本检查重启。
- nginx的max_fails和fail_timeout的意思失败max_fails次之后,将故障节点摘除fail_timeout时间。fail_timeout过后,还会再次发送请求,如果还是有问题,继续摘除。相当于有一个动态恢复检测的机制。
- 这里只是对读操作进行了自动切换,写操作切换需要手工修改配置项发布。
TIPS 为了避免同步脚本被killed,还写了个cron脚本检查重启:
$ cat lsyncd_monitor.sh
#!/bin/bash
source /home/work/.bashrc
LOG_PATH="/home/work/userbin/logs/lsyncd_monitor.log"
LSYNCD_RESULT=`ps aux|grep lsyncd | grep mfs`
# check if lsyncd is still running
if [ "$LSYNCD_RESULT"x == ""x ];then
echo "[ERROR]"`date`" lsyncd is not running!!! Start running it." >> $LOG_PATH
lsyncd /home/work/userbin/mfs-to-static.lua
else
echo "[NORMAL]"`date`" lsyncd is still running." >> $LOG_PATH
fi
然后大概每10s检查一次:
* * * * * for i in {0..5}; do sh /home/work/userbin/lsyncd_monitor.sh && sleep 10; done;
回滚步骤
跟切换MFS一样的步骤:
步骤
- 保险起见,停止静态资源写服务(Spider和Guanxing)
- 停止同MFS==>STATIC同步脚本,将同步方向变为MFS==>STATIC
- 修改服务访问老的STATIC目录,其中服务包括nginx,发布和重启应用。
- 验证服务
方案验证
为了验证上面的方案的可行性,做了一次演练。主要是验证上面配置的读备份机制是否可行。因为只要读服务能够自动切换,保证没有问题,对最终用户的影响不会太大。写服务器挂了,首先只要监控到位,即使处理就可以了。也就是新闻、视频内容在故障期间没有及时更新。
验证方案很简单,只要将nginx@31停掉,看静态资源的访问是否有问题,如果没有问题,说明nginx@05的backup机制起作用了。验证结果证实是生效可行的。
部署图
切换之前部署图
切换之后部署图
后续Action
- MFS的监控。比如MFS进程挂掉了,等。 – 甲黎 done
- 同步脚本的监控。比如同步脚本挂掉自动重启。 – 郑志彬 done
- 随着业务的发展,文件数量会越来越多,MFS能不能方便的线性扩展 – 甲黎