最近在学习分布式存储和数据分析相关的东西,特别是看了Facebook的这篇论文:Finding a needle in Haystack: Facebook’s photo storage,感觉特别与阿里巴巴现在的现状类似。阿里现在的图片存储正处于Facebook的原始阶段——CDN(中美有各自的CDN) ==> imageServer(apache+squid) ==> NFS共享存储。
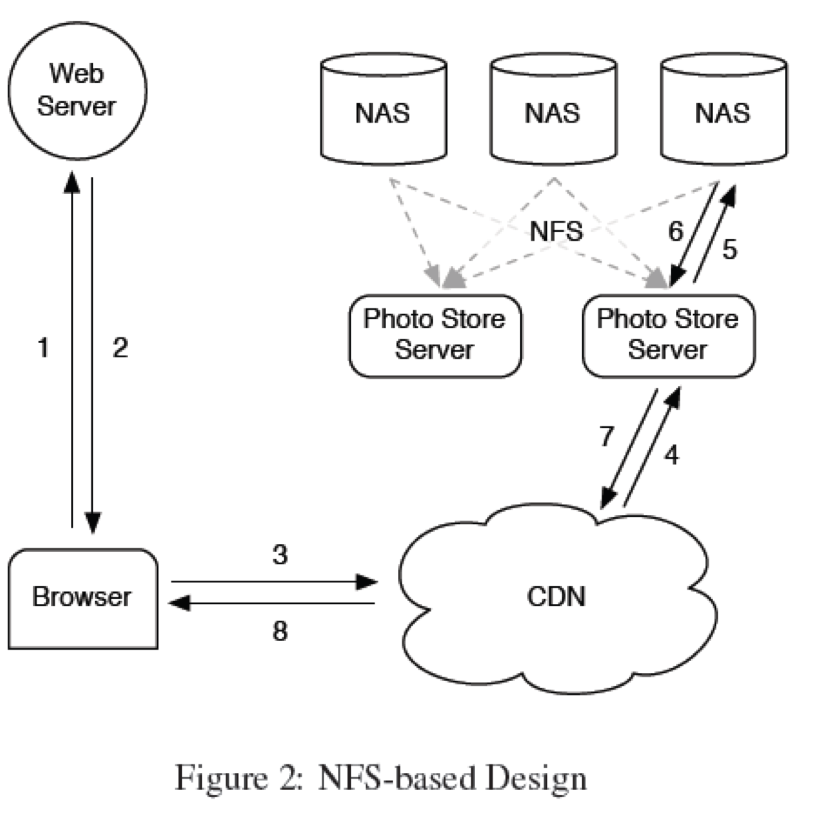
说明 CDN的作用
CDN只适合于缓存popular static content(images, html, css, js, etc.)。对于long tail(长尾)文件,并不适合。这就是我们上次ASC从前台dump图片,将存储搞挂的原因。facebook使用一个类似于上传时间戳的东东作为cookies,来防止这类攻击。
海量小文件的主要问题在于metadata的开销,操作系统根据一个filePath读取相应的文件时,需要如下三个步骤:
- 根据filePath获取inode number(0+次IO,取决于dentry缓存情况,目录越深可能的IO次数越多。一般来说需要1次IO。)
- 根据inode number读取inode块(1次IO)
- 根据inode块中的信息(Inode table)读取相应的data(1+次IO,对于小文件,data只需要一次索引就可以全部读取完毕,如果是大文件还需要二级索引)
可以看到前两个步骤是为了获取文件的metadata,需要的IO次数平均是2次。最后一个步骤才是真正的数据读取。平均下来一个文件读取需要3次IO。
如果能够把dentry和inode都缓存起来,那么就只有真正的数据存储需要IO了。
操作系统其实是有缓存filesystem metadata(存放在inode中)的,但是如果文件特别多的话,缓存不断的换入换出,反而容易产生颠簸。而且这些filesystem meta信息加起来大概是150B,非常不利于cache在内存中。而这些信息其实对于应用来说并不关心,比如user, group, atime等。
极端的,如果只需要获取图片内容,那么可以简单的使用filePath作为key,直接根据内存映射表,得到文件的数据位置。想象一下类似于redis这样的KV引擎,key是filePath,value是文件的数据位置。
Haystack的思路其实非常的简单和直观——因为海量小文件的主要性能瓶颈在于大量的metadata读取,那么关键是减少metadata的量,让其可以缓存到内存中。
A Store machine can access a photo quickly using only the id of the corresponding logical volume and the file offset at which the photo resides. This knowledge is the keystone of the Haystack design: retrieving the filename, offset, and size for a particular photo without needing disk operations. A Store machine keeps open file descriptors for each physical volume that it manages and also an inmemory mapping of photo ids to the filesystem metadata (i.e., file, offset and size in bytes) critical for retrieving that photo.
因为在操作系统级别,每个文件都有一个metadata(inode),那么可以将多个小文件合并成一个大文件,这样就可以大大减少filesystem metadata的数量了,inode也随着减少了。
然而引出了一个问题就是如何定位大文件中的小文件,每个小文件还是需要一定的metadata来描述和定位的,这就引出了application metadata的概念。
- Application metadata: 应用层面概念。存放用于构造URL的信息,浏览器可以直接获取。
- Filesystem metadata: 操作系统中文件系统层面概念。存放让一个host可以直接retrive保存在该host硬盘上的图片。
相对于filesystem metadata来说,application metadata只关心必要的信息,像user, group, mode, atime, ctime, mtime等信息对图片来说并不是必要的,所以可以高度精简,这样所有的application metadata就有可能全部缓存在内存中,这样每次文件读取就只是真正的数据读取了。
合并大文件中每个小文件的获取一般是采用如下方式:
对应用来说它面对的是application metadata: <logic_volume_id, photo_id>
对store engine来说:它接受应用发过来的<logic_volume_id, photo_id>,通过一个mapping hash转成filesystem metadata:<physical_volume_id, offset, size>
下面是Haystack的存储结构设计:
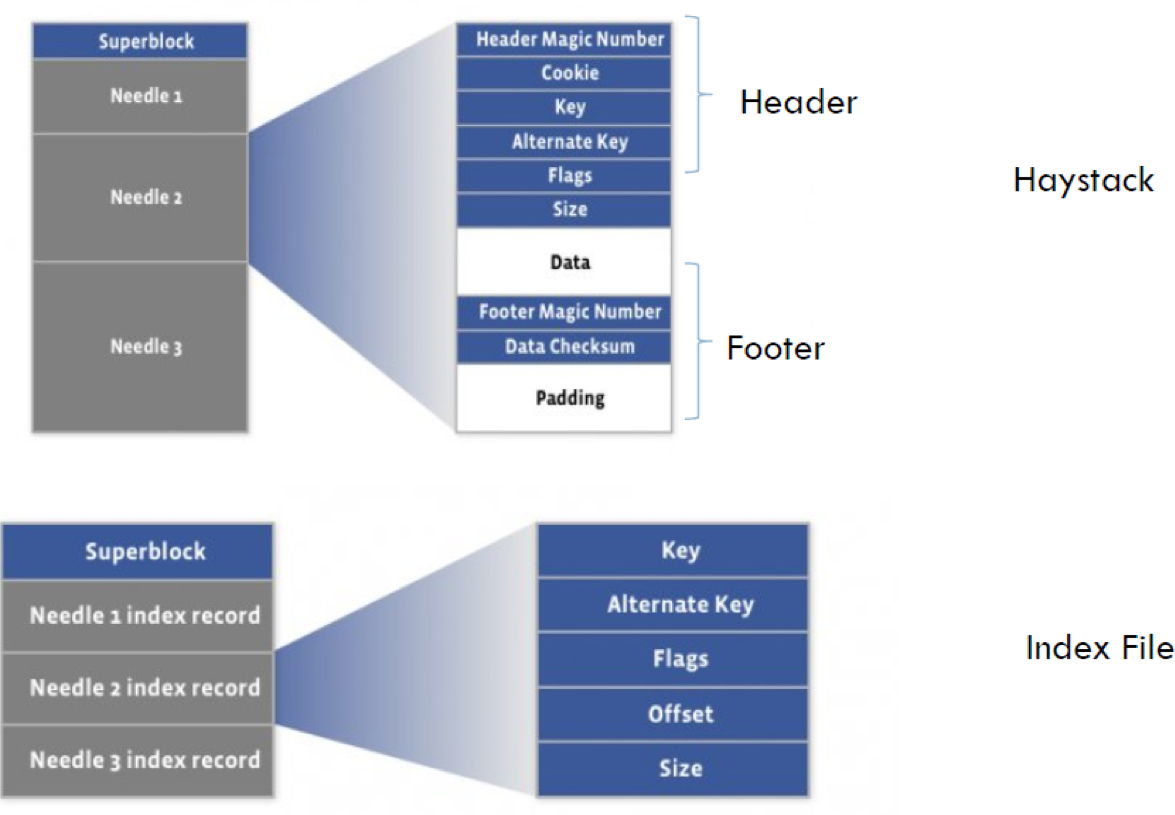
其中index各个字段含义如下:

所有的元数据字段如下:

可以看到Haystack的元数据真的是非常的少,除了位置信息(key, offset, size)之外,就是一个反正攻击的cookies和逻辑删除的flags,还有完整校验的checksum,还有数据恢复用的Magic Number。原来操作系统级别的metadata,像user, group, mode, atime, ctime等都不保存。所以是非常利于缓存和索引的。
整个Haystack架构如下:
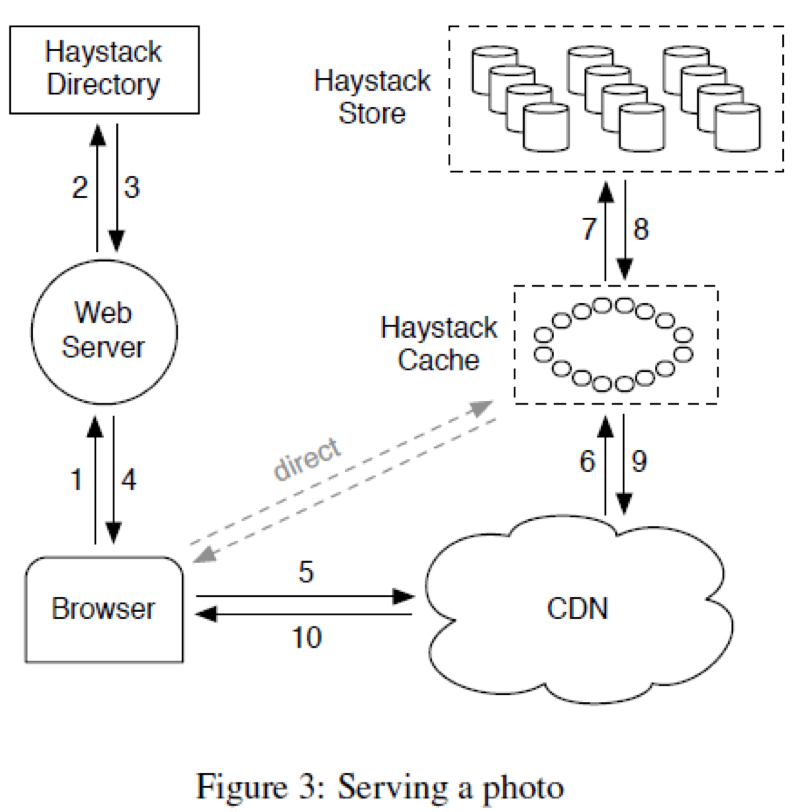
可以看到包含如下几个组件:
- Haystack Directory,类似于前面的imageServer,主要提供下面四个功能:
- Provides a mapping from logical volumes to physical volumes
- Load balances writes across logical volumes
- Determines whether a photo request should be handled by the CDN or by the Haystack Cache
- Identifies logical volumes that are read-only
- Operational reasons
- Reached storage capacity
- Haystack Cache
- Distributed hash table, uses photo’s id to locate cached data
- Receives HTTP requests from CDNs and browsers
- If photo is in Cache, return the photo
- If photo is not in Cache, fetches photo from the Haystack Store and returns the photo
- Add a photo to Cache if two conditions are met…
- The request comes directly from a browser, not the CDN
- The photo is fetched from a write-enabled Store machine
- Haystack Store
- Each Store machine manages multiple physical volumes
- Can access a photo quickly using only the id of the corresponding logical volume and the file offset of the photo
- Handles three types of requests…
- Read
- Write
- Delete
其中读过程如下:
- Cache machine supplies the logical volume id, key, alternate key, and cookie to the Store machine
- Store machine looks up the relevant metadata in its in-memory mappings
- Seeks to the appropriate offset in the volume file, reads the entire needle
- Verifies cookie and integrity of the data
- Returns data to the Cache machine
写过程如下:
- Web server provides logical volume id, key, alternate key, cookie, and data to Store machines
- Store machines synchronously append needle images to physical volume files
- Update in-memory mappings as needed
删除操作流程如下:
- Store machine sets the delete flag in both the in-memory mapping and in the volume file
- Space occupied by deleted needles is lost! 定期Compaction进行空间回收。
说明
1、对于上面第一个步骤:根据filePath获取inode number(finding an inode by reference to a given filename)实际上是个很复杂的过程。大概过程如下:
使用nameidata{}作为lookup函数的参数和返回值:
<fs.h>
struct nameidata {
struct dentry
struct vfsmount
struct qstr
unsigned int
...
}
The kernel uses the path_lookup function to find any path or filename.
fs/namei.c
int fastcall path_lookup(const char *name, unsigned int flags, struct nameidata *nd)
检查name返回是否以/开始,如果是说明是绝对路径,通过current->fs->root (the process root directory)得到。 否则,是相对路径,使用当前路径,通过current->fs->pwd (the process-current directory)获取。
拿到起始目录的dentry结果(root or pwd),从而得到该dentry对应的inode,那么根据这个inode我们可以得到它对应的子目录,通过比较得到相应的目录项,从而又得到子目录的inode,一层一层往下走就得到最后的文件了。
为了提高性能,内核使用了dentry缓存(一个hash map和LRU list)来减少不必要的IO。
2、将多个小文件合并成一个大文件(即不使用传统的文件系统)会带来如下几个问题:
-
第一个也是个人感觉最重要的一个问题是很多静态文件服务器,如apache,nginx等,因为他们面向的是操作系统的文件系统,所以他们认为一个URL对应一个文件,现在一个URL可能只是对应一个文件的一个小部分(自定义文件系统)。这样就需要特殊的处理逻辑(利用fileSystem metadata获取)。这个facebook也没有好的解决方案,他们是采用RESTful的GET方式获取图片。在URL中传递必须的信息,但是由相应的代码逻辑进行处理。TFS则是自己写了一个nginx模块支持nginx读取。
-
另外一个问题是这种文件一般是append only,因为删除或者更新中间的小文件会带来很大的麻烦(需要空间的移动)。简单的解决方案就是不允许更新和删除:
- 更新相当于重新上传文件(版本号加一,以避免客户端缓存)
- 删除简单的标记删除,即逻辑删除而不是物理删除。
- 定时压缩 (Compaction, Important because 25% of photos get deleted in a given year)
3、大部分分布式文件系统都是单独的API,有少部分文件系统提供POSIX文件接口,比如MooseFS,这样可以对客户端完全透明。