Parameter Server 中文名称叫做参数服务器,是分布式机器学习框架中用来做参数同步的框架。
为什么需要引入 Parameter Server
- 各个 worker 之间需要共享模型参数 => 全局参数服务器
- 模型参数很大,超过单台机器的容纳能力 => 分布式参数服务器
- 训练数据太大,需要并行提速(大数据)=> 分布式参数服务器
设计要求
- Efficient communication: 高效的网络通信。因为不管是模型还是样本都十分巨大,因此对网络通信的高效支持以及高配的网络设备都是大规模机器学习系统不可缺少的
- Flexible consistency models: 灵活的一致性模型。不同的一致性模型其实是在模型收敛速度和集群计算量之间做tradeoff;要理解这个概念需要对模型性能的评价做些分析
- Elastic Scalability: 弹性可扩展。增加节点无需重启网络
- Fault Tolerance and Durability: 容灾容错。大规模集群协作进行计算任务的时候,出现Straggler或者机器故障是非常常见的事,因此系统设计本身就要考虑到应对;没有故障的时候,也可能因为对任务时效性要求的变化而随时更改集群的机器配置。这也需要框架能在不影响任务的情况下能做到机器的热插拔。
- Ease of Use: 易用性。主要针对使用框架进行算法调优的工程师而言,显然,一个难用的框架是没有生命力的。
实现策略
- Efficient communication: 异步通信。因为是异步通信,所以不需要停下来等一些慢的机器执行完一个iter,这就大大减少了延迟。 当然并非所有算法都天然的支持异步和随机性,有的算法引入异步后可能收敛会变慢,因此就需要自行在算法收敛和系统效率之间权衡。
- Flexible consistency models: 提供BSP,ASP,SSP三种一致性同步机制,允许开发人员在算法收敛和系统性能之间进行选择。
- Elastic Scalability: 使用一致性哈希算法,使得新的Server可以随时动态插入集合中,无需重新运行系统。
- Fault Tolerance and Durability: 节点故障是不可避免的。对于server节点来说,使用链备份来应对;而对于Worker来说,因为worker之间互相不通信,因此在某个worker失败后,新的worker可以直接加入。
- Ease of Use: 全局共享的参数可以被表示成各种形式:vector, matrices 或是 sparse 类型,同时框架还提供对线性代数类型提供高性能的多线程计算库。
架构
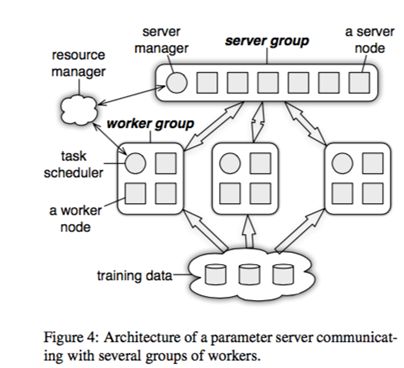
上图的 resource manager 在实际系统中往往是复用现有的资源管理系统,比如 yarn、mesos 或者 k8s;底下的 training data 毋庸置疑的需要类似GFS的分布式文件系统的支持,一般是 HDFS;剩下的部分就是参数服务器的核心组件了。
图中画了一个 server group 和三个 worker group;实际应用中往往也是类似,server group 用一个,而 worker group 按需配置;server manager 是 server group 中的管理节点,负责维护一些元数据的一致性,例如各个节点的状态,参数的分配情况。一般不会有什么逻辑,只有当有server node加入或退出的时候,为了维持一致性哈希而做一些调整。
Paraeter Server框架中,每个server都只负责分到的部分参数(server共同维持一个全局共享参数)。server 节点可以和其他server节点通信,每个 server 负责自己分到的参数,server group 共同维持所有参数的更新。server manage node 负责维护一些元数据的一致性,例如各个节点的状态,参数的分配情况。
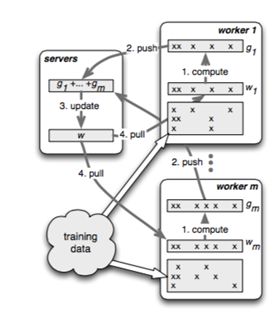
worker 节点之间没有通信,只和对应的 server 有通信。每个 worker group 有一个 task scheduler,负责向 worker 分配任务。一个具体任务运行的时候,task schedule 负责通知每个 worker 加载自己对应的数据,然后去 server node 上拉取一个要更新的参数分片,用本地数据样本计算参数分片对应的变化量,然后同步给 server node;server node 在收到本机负责的参数分片对应的所有 worker 的更新后,对参数分片做一次 update。
task scheduler还会监控 worker 的运行情况。当有 worker 退出或加入时,task scheduler 重新分配任务。
如图所示,不同的 worker 同时并行运算的时候,可能因为网络、机器配置等外界原因,导致不同的 worker 的进度是不一样的,如何控制 worker 的同步机制是一个比较重要的课题。详见下节分解。
模型参数——(Key,Value) Vectors
参数都被认为是 (key, value) 集合。例如对于常见的LR来说,key 就是 feature ID(slotId),value 是其权值。对于不存在的key,可认为其权值为0。
大多数的已有的框架都是这么对 (key, value) 进行抽象的。但是 PS 框架除此之外还把这些 (k,v) 对看作是稀疏的线性代数对象(通过保证key是有序的情况下),因此在对 vector 进行计算操作的时候,也会在某些操作上使用 BLAS 库等线性代数库进行优化。
接口——Range Push/Pull
PS框架中,workers和servers之间通信是通过 push() 和 pull() 方法进行的。worker通过 push() 将计算好的梯度发送到 server,然后通过 pull() 从 server 获取更新参数。
为了提高通信效率,PS允许用户使用 Range Push/Range Pull 操作。
w.push(R, dest)
w.pull(R, dest)
同步协议
众所周知,在分布式计算系统中,由于多个计算节点计算进度不可能完全一致,会导致了在汇总结果时需要等待那些计算速度较慢的节点,即慢节点会拖慢整个计算任务的进度,浪费计算资源。
考虑到机器学习的特殊性,系统其实可以适当放宽同步限制,没有必要每一轮都等待所有的计算节点完成计算,部分跑得快的Worker,其实完全可以先把训练好的增量Push上去,然后进行下一轮的训练运行。这样可以减少等待时间,让整个计算任务更快。
因此,异步控制在分布式机器学习系统中,是非常重要的功能之一。Parameter Server 一般会提供如下三个级别的异步控制协议: BSP(Bulk Synchronous Parallel),SSP(Stalness Synchronous Parallel) 和 ASP(Asynchronous Parallel), 它们的同步限制依次放宽。为了追求更快的计算速度,算法可以选择更宽松的同步协议。
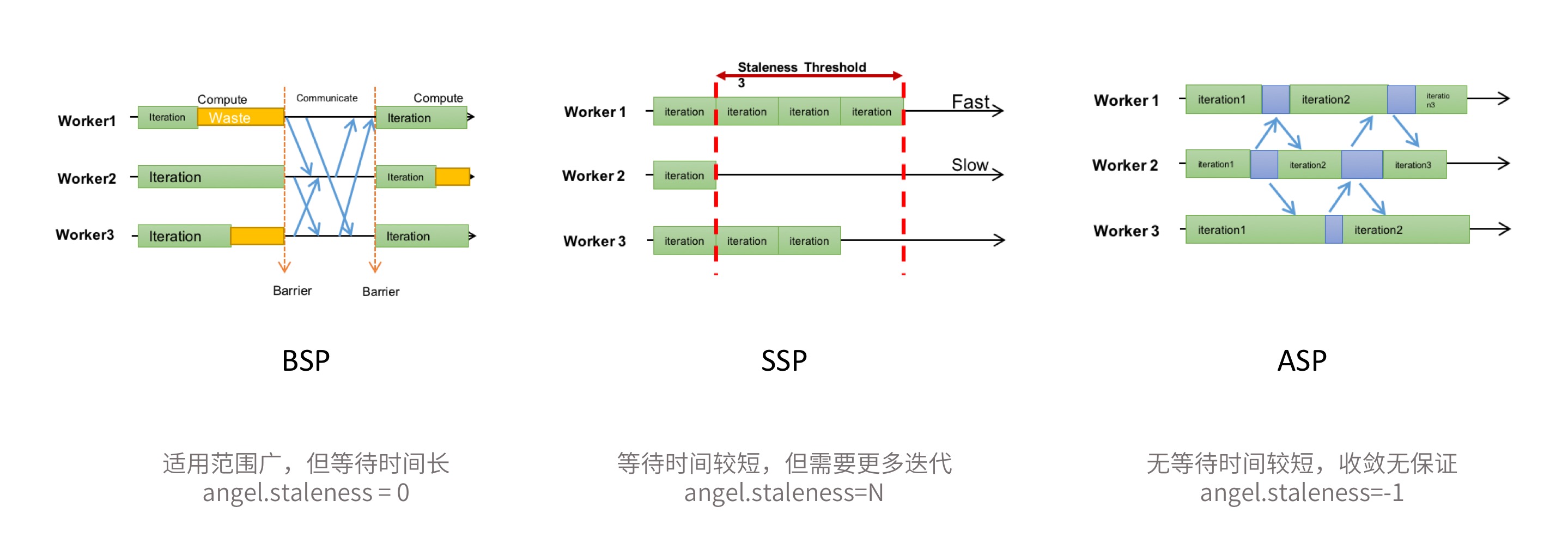
1. BSP
一般的分布式计算采用的同步协议,例如 Spark。在每一轮迭代中都需要等待所有的Task计算完成。
- 优点:适用范围广;每一轮迭代收敛质量高
- 缺点:但是每一轮迭代都需要等待最慢的Task,整体任务计算时间长
2. SSP
允许一定程度的Task进度不一致,但这个不一致有一个上限,我们称之为 staleness 值,即最快的Task最多领先最慢的Task staleness 轮迭代。
- 优点:一定程度减少了Task之间的等待时间,计算速度较快
- 缺点:每一轮迭代的收敛质量不如BSP,达到同样的收敛效果可能需要更多轮的迭代;适用性也不如BSP,部分算法不适用
3. ASP
Task之间完全不用相互等待,先完成的Task,继续下一轮的训练。
- 优点:消除了等待慢Task的时间,计算速度快
- 缺点:适用性差,在一些情况下并不能保证收敛性
NOTES
同步限制放宽之后可能导致收敛质量下降甚至任务不收敛的情况,这需要在实际算法中,需要指标的变化情况,调整同步协议以及相关的参数,以达到收敛性和计算速度的平衡。
PS@Tencent
腾讯和北京大学联合开发并开源了一个基于参数服务器(Parameter Server)理念开发的高性能分布式机器学习平台,叫做 Angle。在这篇 Angle的架构设计 文章中,比较详细的介绍了Angle 基于 PS 的架构:
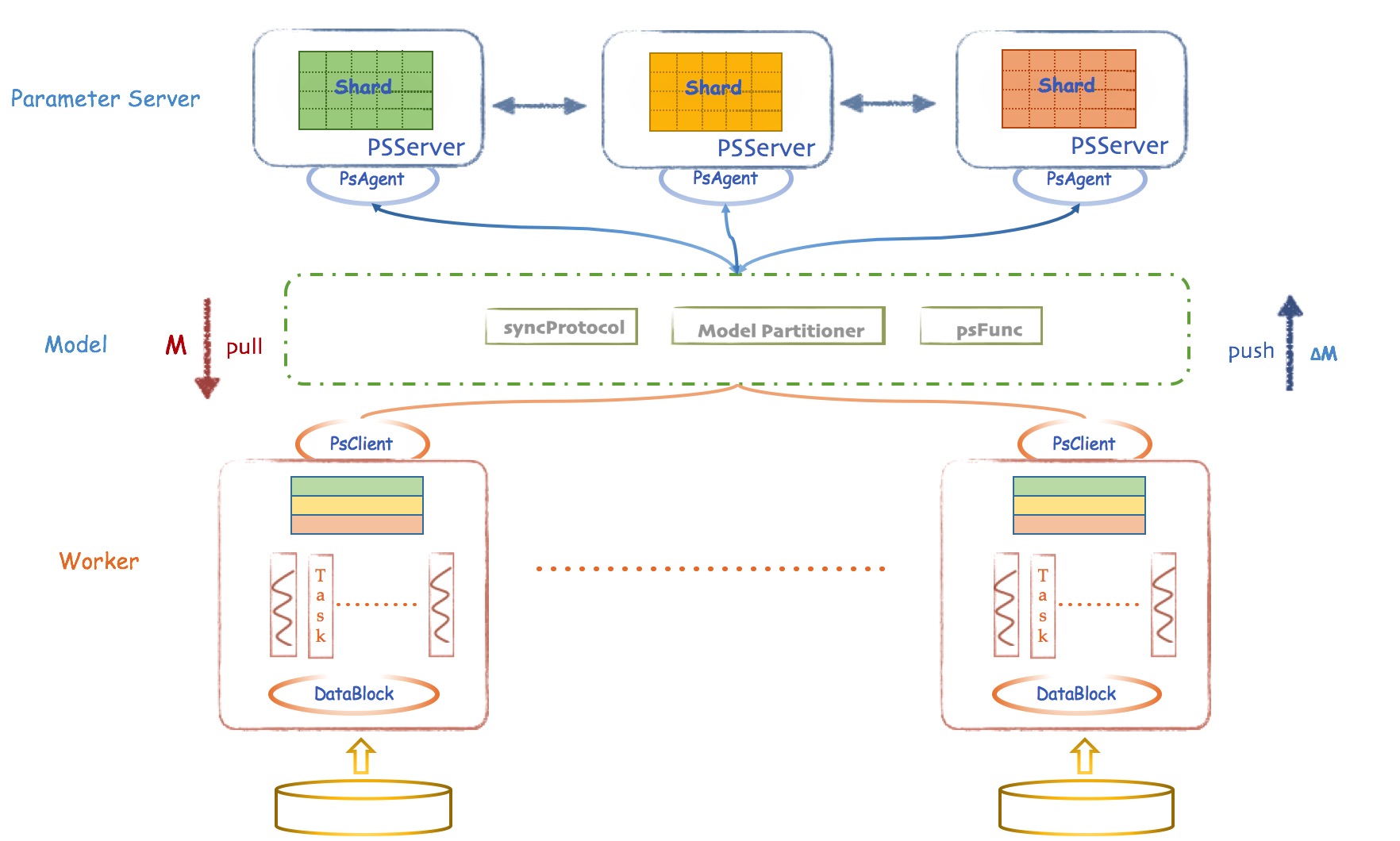
它的架构设计,从整体可以分为3大模块:
1、Parameter Server层:提供通用的参数服务器服务,负责模型的分布存储,通讯同步和协调计算,并通过 PSAgent 提供 PS Service
2、Worker层: 基于 Angel 自身模型设计的分布式运行节点,自动读取并划分数据,局部训练出模型增量,通过 PS Client 和 PS Server 通信,完成模型训练和预测。一个 Worker 包含一个或者多个 Task,Task 是 Angel 计算单元,这样设计的原因是可以让 Task 共享 Worker 的许多公共资源。
3、Model层: 这是一层虚拟抽象层,并非真实存在的物理层。关于 Model 的 Push 和 Pull,各种异步控制,模型分区路由,自定义函数等,是连通 Worker 和 PSServer 的桥梁。
除了这3大模块,还有2个很重要的类,在图上没有显示,但是值得关注,它们是:
1、Client:Angel任务运行的发起者
- 启动和停止PSServer
- 启动和停止Angel的Worker
- 加载和存储模型
- 启动具体计算过程
- 获取任务运行状态
2、Master:Angel任务运行的守护者
- 原始计算数据以及参数矩阵的分片和分发
- 向Gaia申请Worker和ParameterServer所需的计算资源
- 协调,管理和监控Worker以及PSServer
PS@Alibaba
在这篇文章 零距离观察蚂蚁+阿里中的大规模机器学习框架 中,蚂蚁金服资深技术专家周俊比较详细的介绍了阿里巴巴的 Parameter Server 的架构。如下图所示:
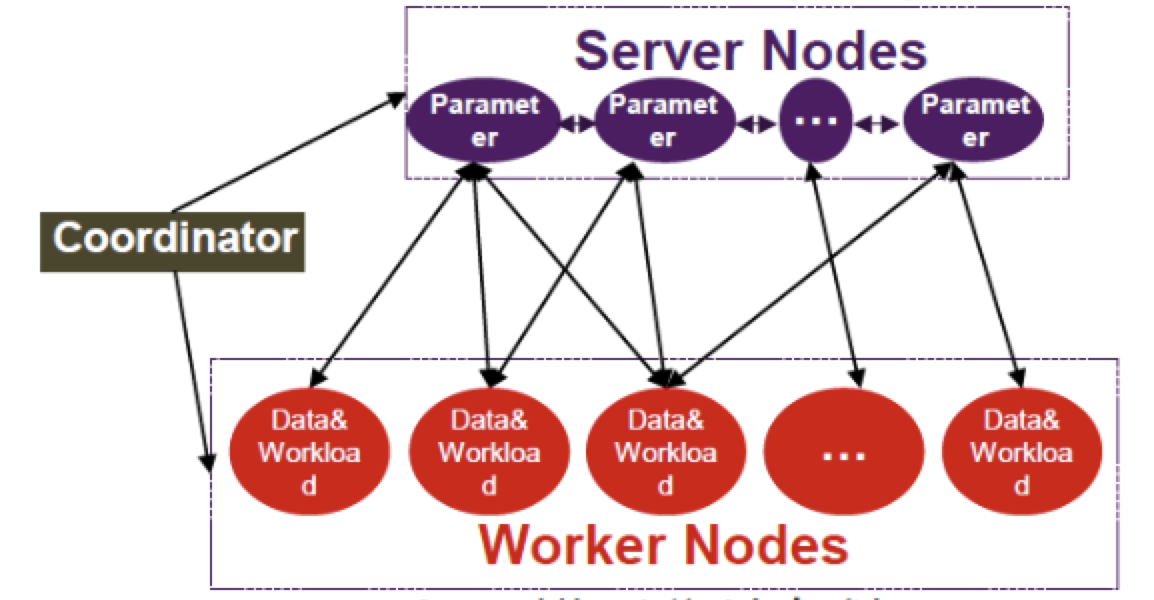
框架的大致结构如上图所示,包括三大模块:Server Node、Worker Node 和 Coordinator,分别用于 模型分片存储、数据分片存储 和 总体流程控制。
- Coordinator
- 迭代控制
- Failover管理、checkpoint
- Server
- Distributed key value store
- 一致性 hash,进行模型分片
- Worker
- 数据分片(加载表的不同行)
- 实现 Compute (Gradient等) 接口
具体来讲,Coordinator 主要进行迭代控制,同时完成 Failover 管理,当 Worker 或 Server 挂掉时,由 Coordinator 进行处理;当 Worker、Server 和整个 Job 都失败的情况下,通过 Checkpoint 机制,在下一次启动时从上一次保存的中间结果继续前进。
Sever 本质上是分布式 Key-value 存储系统,它将一个非常大的模型,通过一致性 Hash 切成多片,在多个 Server 上分担压力,进行模型分片。
Worker 是将数据源的不同行加载到不同的 Worker 上,实现数据分片,同时通过计算接口完成梯度计算。
不过这里相对于 Angle 模型分片有点简单,能满足所有的算法模型吗?
推荐阅读
- 大规模机器学习的编程技术、计算模型以及 Xgboost 和 MXNet 案例
- 参数服务器——分布式机器学习的新杀器
- 大规模机器学习框架的四重境界
- 分布式机器学习平台大比拼:Spark、PMLS、TensorFlow、MXNet
- 分布式机器学习的参数服务器
- ParameterServer入门和理解
- MXNet之ps-lite及parameter server原理
- 零距离观察蚂蚁+阿里中的大规模机器学习框架
- Angle