一些基本概念和背景知识
Switchover, Failover和Failback
当一个系统宕掉之后,手动的切换到冗余或者备份系统,这个过程称之为Switchover。如果是自动切换,不需要人工干预,那么称之为failover。
When a manual process is used to switch from one system to a redundant or standby system in case of a failure, we are talking about switchover. Automatic switchover, without human intervention, is called failover.
原系统恢复之后,从备份系统切换回去的过程称之为Failback。
Asynchronous VS Synchronous
为了构建一个冗余的数据库系统,数据需要移动到另一个服务器/存储。在数据传输方面有两个基本概念:asynchronous和synchronous。
Asynchronous data replication: server A将数据发送给server B,但是并不等待server B的确认回复(‘acknowledge message’),就直接提交事务。
优点
- 独立
- 性能
缺点
- 同步丢失带来的数据一致性问题
- 同步失败但是无法回滚带来的一致性问题。
Synchronous data replication: 与异步同步不同,第二个server在接收到同步数据后,需要发送一个’acknowledge message’给主节点,主节点收到ACK确认后才提交事务。
带来最大的缺点是性能不仅仅取决于两个节点的执行性能,还极大的依赖于节点之间的网络传输时延。所以不推荐跨机房或者走公网搭建synchronous数据同步。
TIPS
MySQL支持三种级别的同步方式:
- Asynchronous replication: 5.5以前的版本
- Semi-synchronous Replication (MySQL 5.6+)
- Synchronous replication (MySQL Cluster NDB)
MySQL 5.5+对同步复制功能的改进以及对基于Replication方式的HA方案的影响
Multi-threaded Slave (MTS)
MySQL 5.6允许你基于数据库级别进行并行复制。这个特性称之为“Multi-Threaded Slave” (MTS)。
通过设置 slave_parallel_workers=N, where N > 1(推荐配置是16) 就可以了开启这个特性。
MySQL 5.7取消了5.6只能一个线程一个数据库的并行复制的限制(one thread per schema),引入了logical-clock概念,一个组提交内事务都可以并行,可以达到接近主库并发效果。
开通并行复制, 需要指定如下几个变量:
slave-parallel-type=LOGICAL_CLOCK // 基于组提交的并行复制方式,默认是DATABASE,则为基于库的并行复制方式(即mysql 5.6的并行复制机制)
slave-parallel-workers=16 // 性能测试结果显示16个worker线程性能最好。如果配置为0,则退化为mysql 5.5的单线程复制机制
master_info_repository=TABLE // master info存储在table里以最小化磁盘IO
relay_log_info_repository=TABLE // relay info也存储在table里以最小化磁盘IO
relay_log_recovery=ON // 与 relay_log_info_repository=TABLE 一起开启`Crash-safe Slave`特性。
需要注意的是新的并行复制机制依赖于GTID,如果变量gtid_mode=OFF, 则会默认启用Anonymous_Gtid模式 (所以,还是乖乖打开GTID为好, 又不会死人)。
这个特性可以极大程度上减少甚至消除master和slave之间的因为单一SQL Thread引起的同步延迟。
Semi-Synchronous Replication
MySQL 5.5以后引入了半同步复制 Semi-Synchronous replication,在很大程度上减少了”binlog events exist only on the crashed master”的风险,避免数据丢失。
不过需要注意的是,Semi-Synchronous replication不没有解决所有的一致性问题。Semi-Synchronous replication只是保证了至少一个(不是所有)slave接收到master在commit时发送过来的binlog事件。其他的slaves仍然有可能没有收到所有的binlog事件。 Without applying differential relay log events from the latest slave to non-latest slaves, slaves can not be consistent each other.
MySQL 5.7版本增强半同步复制,确保从库先收到,并且允许设置半同步从库个数。称之为Lossless Semi-Synchronous Replication。同时性能方面也有了一定的改善。
解决问题
主要是解决了slave的同步延迟问题,使得一致性得到进一步的保障。在这之前,要不是使用复杂的切换脚本从Master将bin-log补齐,要不就是简单的采用Shared storage/DRBD的方式。
Global Transaction Identifier (GTID)
全局事务ID(GTID)是MySQL5.6引入的一个非常实用的特性。GTID is a unique identifier created and associated with each transaction committed on the server of origin (master). This identifier is unique not only to the server on which it originated, but is unique across all servers in a given replication setup. There is a one-to-one mapping between all transactions and all GTIDs。这个新特性使故障转移和slave提升变得容易很多。
需要注意的是MySQL和MariaDB具有不同的GTID实现。
解决问题
主要是解决了slave切换master的复杂性。在GTID之前,我们需要根据slave当前的执行SQL到新的master中找到bin-log的同步位置(CHANGE MASTER TO ... MASTER_LOG_FILE=xxx, MASTER_LOG_POS=xxx)。这个是一个麻烦同时又容易出错的过程。使用GTID就不需要了。你只需要将MASTER_AUTO_POSITION选项enable。
很多脚本会判断MySQL版本是否支持GTID,根据这个来执行master切换。
多源复制 (Multi-Source Replication)
这个也是一个非常大的改进。在5.7之前,一个Slave只能专属于某个master,一个master下面可以有多个slaves,master和slaves是一对多的关系。但是在5.7之后,replication slave 可以同时接收来自多个master的复制。
合久必分,分久必合。有分库分表的场景就有合并的需要。Multi-source replication特别适用于后台报表或者管理查询系统。这些系统往往不是根据shardingId来查询的,把数据聚合一起可以简化查询流程和提供查询性能。当然,这也有一个问题就是同步时延;还有就是数据量要能够存放在单库单表中。
需要注意的是Multi-source replication并不对可能带来的冲突进行检测或者解决,留给应用自己处理。
Crash-safe Slave
Crash safe means even if a slave mysqld/OS crash, you can recover the slave and continue replication without restoring MySQL databases onto the slave. To make crash safe slave work, you have to use InnoDB storage engine only, and in 5.6 you need to set relay_log_info_repository=TABLE and relay_log_recovery=1.
Durability (sync_binlog = 1 and innodb_flush_log_at_trx_commit = 1) is NOT required.
总结
总之,MySQL5.6以后对复制功能做了很大的完善,极大的提高了Master和Slave之间的同步延迟问题。
- MTS(Mutl-threaded Slave)解决了单一SQL Thread apply同步事件慢的问题
- Semi-Synchronous Replication解决了Master和Slave之间的同步延迟问题
- GTID使得故障转移和slave提升变得容易很多
- Crash-safe Slave 让slave恢复变得快速容易很多
- Multi-Source Replication可以在MySQL基本实现数据汇聚,是分库分表的一个反向支持
MySQL高可用性的解决方案
现在我们开始进入我们的专题,MySQL的HA方案讨论。
MySQL的HA方案可以在几个层面上做到:
- 基于MySQL replication的拓扑方式
- MASTER-SLAVE replication:需要Slave Promotion
- MASTER-MASTER replication:使用热备(hot standby)让master切换变得容易一些
- MASTER-RELAY replication
- …
- 使用一些工具实现failover
- MMM。HA: 99%
- MHA。HA: 99.9%
- PRM 貌似只支持到 MySQL 5.6,不支持最新的MySQL 5.7。
- MySQL Fabric
- Orchestrator
- MariaDB Replication Manager (MRM) 只支持MariaDB with GTID based replication topologies。
- 需要使用其他工具来进行
IP address takeover(一般是VIP+KeepAlived或者PaceMaker,或者使用数据库中间件(如Cobar/MyCat, etc.)对应用保持透明 - 需要注意这些工具对MySQL版本和配置的要求
- MySQL or MariaDB,比如MRM只支持MariaDB;MHA、PRM等不支持 MariaDB GTID based replication topologies, MySQL Fabric要求MySQL 5.6.x+, etc.
- Replication methods (statement and row based replication)
- supporting GTID?
- etc.
- 基于集群的部署方式 (true Multimaster Cluster based on (virtually) synchronous replication)。HA: 99.999%
- 官方:Mysql Cluster
- 开源:Galera Cluster for MySQL
- 有一些局限性和对业务并不是很透明,另外因为是同步复制,所以性能上会有一些影响。每个节点都需要并发的跟其他节点通讯,对网络要求比较高。
- 需要配合使用Load Balancer (MaxScale, HAProxy和VIP) 对应用透明和负载均衡。MySQL Load Balancing with HAProxy - Tutorial
- 存储方式上的同步
- Synchronous Replication using DRBD(Distributed Replicated Block Device)。HA: 99.9%
- Shared Storage (SAN, etc.)。HA: 99.5% ~ 99.9%。存在存储单点问题,不推荐。
1. 基于MySQL replication的拓扑方式
首先看一下基于MySQL同步的HA方案。这是最老也是最经得起时间考验的方案。
MySQL复制拓扑结构
MySQL支持多重拓扑结构,不同的拓扑结构有不同的应用场景。
首先MySQL Replication中有三种服务器角色:
- Master
- Slave: 扩展读操作的Slave
- Relay: 同时扮演master角色的slave称之为中继服务器(Relay)
这些角色常常构成下面几种常见的拓扑结构:
- Master-Slaves
- 一个master下面挂多个只读slaves,最常见的拓扑结构
- 读写分离的典型架构
- master挂掉之后,需要进行比较复杂的slave选举和切换,使用MHA可以自动化这个过程。
- Master-Relay-Slaves (Chain Replication)
- 减少Master同步压力
- Relay作为master备份,切换之后slaves不需要重新切换到新的master。
- 使用半同步可以避免同步延迟放大。
- Master with Active Master (Circular Replication)
- 所有的Master对等接收读写请求
- 需要设置合理的auto-increment offset来避免自增主键冲突,或者使用全局的主键分配器
- 推荐只有master提供服务,其他master作为热备(类似于下面的Master with Backup Master)
- Master with Backup Master (Multiple Replication)
- 单master,一个热备master,一个或者多个slave
- master和backup master之间使用Semi-synchronous replication 减少同步延迟
- 这个拓扑结构的好处在于不需要slave promotion过程,直接把backup master顶上去就可以了,而且半同步保证backup master基本是up-to-date的。
- Multiple Masters to Single Slave (Multi-Source Replication)
- Galera with Replication Slave (Hybrid Replication)
- Hybrid replication is a combination of MySQL asynchronous replication and virtually synchronous replication provided by Galera.
- Galera Cluster提供正常的读写请求,本身通过 近实时同步 保证HA
- 异步复制的slave可以作为报表/OLAP等类型的查询数据库,或者mysqldump,同时也是一个容灾备份。
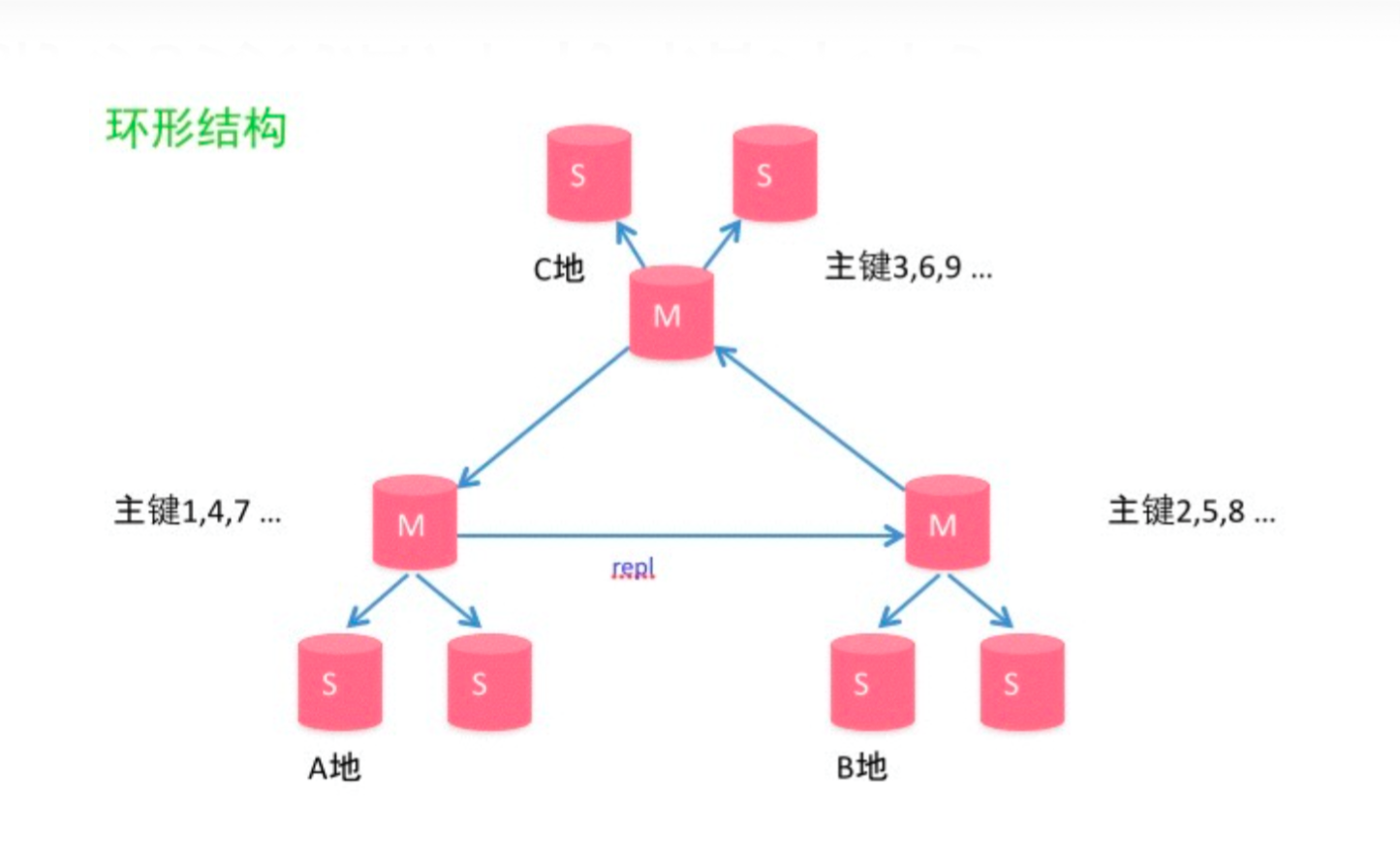
TIPS 关于Multiple-Active-Master (Circular Replication)的拓扑方式
有时候我们还是需要多个Master同时提供读写服务的,最常见的方案就是多地部署的情况,一般是为了就近部署以便提速或者异地容灾。每个地区都有一个主Master,该主Master有Backup Master跟其做HA(一般是半同步保证实时性),可能还有一些只读的Slaves。但是每个地区的主Master之间需要数据进行互相同步,比如阿里巴巴的中美数据同步。这时候由于是异地部署,显然办同步是不合适的,所以会用普通的异步同步方式。这就需要保证用户的请求是区域固定的,而不是在各个地区之间负载,否则会出现不一致问题。同时,由于每个master都是提供对等的读写,所以需要解决主键冲突问题。一种简单的方案就是主键取模错开,比如奇偶递增。很多公司会使用这种,比如Flikr,美丽说,等。但是这种方案有个问题,就是扩容的时候需要ID需要调整。比如有两个Master变成三个Master,那么原来的奇偶自增ID就不适用了。所以如果不引入全局ID分配器的情况下,使用数据库自增功能的话,最合适的做法还是对ID进行预分配,比如A地区的ID范围是[1, 1000_000_000], B地区的是[1000_000_000, 2000_000_000], etc.
基于MySQL复制方式的故障failover方案
分为三种情况:
- Master故障
- Slave故障
- Relay故障
1. Master故障failover
如果master发生故障,必须迅速替换它以保证整个系统的正常运行。这时候要做的第一件事情就是找一个新的可用的master,将所有的客户端连接到新的master上。同时,slaves虽然还可以提供读服务,但是在没有切换到新的master之前,它们只能提供过时的数据,所以还需要把slave指向新的master。
具体切换步骤如下:
- (中间件或者监控程序)监控到master挂掉了
- 找出一个可用的master替代
- 将客户端连接到新的master
- 将其他的slave挂到新的master下
具体分析一下:
- 步骤一:(中间件或者监控程序)监控到master挂掉了
- 我们需要有一种方式能够监控到Master挂掉了,这需要一个很好的监控系统,至少针对master。
- MONyog Ultimate Monitor会是一个不错的选择。
- 步骤二: 找出一个可用的master替代
- 我们需要选举一个最新的slave出来,同时在promote它为新的master之前,要保证relaylog中的所有事务已经被SQL Thread apply。
- 如果拓扑结构一开始就已经有backup master,那么会比slave选举简单很多,直接把backup master推举上去就可以了。
- 严格意义来说,在切换master之前需要检查一下新master是up to date的,如果不是,要补齐未apply的事务先。使用半同步可以避免这个问题。
- 步骤三: 将客户端连接到新的master
- 我们希望对客户端透明,同时也能够最大的减少不可用时间。
- 这里一般是使用VIP的方式,或者引入数据库中间件来达到自动切换的目的。
- 步骤四: 将其他的slave挂到新的master下。这里一般有两个步骤需要操作:
- 把promoted的slave设置为可写。// 如果是dual-master,那么可以省略这个步骤
- 其它的slaves切换到新的master进行同步。这里需要重新找到在新master的同步位置 // 如果slaves是挂在backup master或者relay server下,则不需要这个步骤;另外,使用GTID可以大大简化这个步骤
前面也提到过,有很多开源的工具可以将这个过程自动化,即由switchover进化为failover。另外,不同的MySQL版本,不同的拓扑结构,不同的工具(主要是master失败检测方式)有不同的成本和效果。需要深入了解和实际测试再做决定(TODO)。一般来说,failover的时间大概在5s~20s。
TIPS & Recommendations
- 尽量使用GTID-based Replication,简化部署和failover。
- 尽量使用InnoDB存储引擎,因为它提供了完整的ACID事务支持和快速奔溃恢复(full transaction capability with ACID compliance and better crash recovery)
- 尽量不要使用环形复制拓扑结构,不要有多个对等的master同时提供读写服务。因为容易带来数据冲突。
- 推荐使用Master with Backup Master (Multiple Replication)拓扑结构,同时强烈建议master和backup master之间使用semi-synchronous replication。
- backup master和slaves都配置成read-only模式,这样可以减少数据冲突的风险。
- 同步数据包一般都会比较大, 所以记得讲
max_allowed_packet设置成一个比较大的数值,避免同步错误。 - 复制链接参数不应该配置在my.cnf中,而是通过命令动态指定。
2. Slave故障failover
由于Slave只是提供读扩展和备份,所以当slave故障之后,要做的事情很简单:检测到slave故障,把它从负载均衡器的池子里删除,恢复后再加回去就可以了。
3. Relay故障failover
对于中继服务器的故障,需要特殊处理。如果它们发生了故障,剩下的slave必须重定向到其他的中继服务器或者master。这里需要考虑一下master的负载问题。
2. 基于集群的部署方式 (true Multimaster Cluster based on (virtually) synchronous replication)
高性能、高可用性、冗余和可扩展性都是数据库规划时需要考虑的重要因素,通常采用商用高可用性硬件和负载均衡的方案来寻求改善复制拓扑的方法。尽管这样基本可以满足大部分需求,但是如果需要无单点故障的方案,而且要求极高的吞吐量,上线时间达到99.999%,那么可以考虑使用MySQL集群技术。
1. Mysql Cluster
MySQL Cluster本质上是在提交的时候通过两阶段提交协议将数据同步复制到多个节点(至少两个数据副本),来实现HA。这点是跟Replication最大的不同,后者是异步,或者半同步。
MySQL Cluster包含以下三种类型的节点:
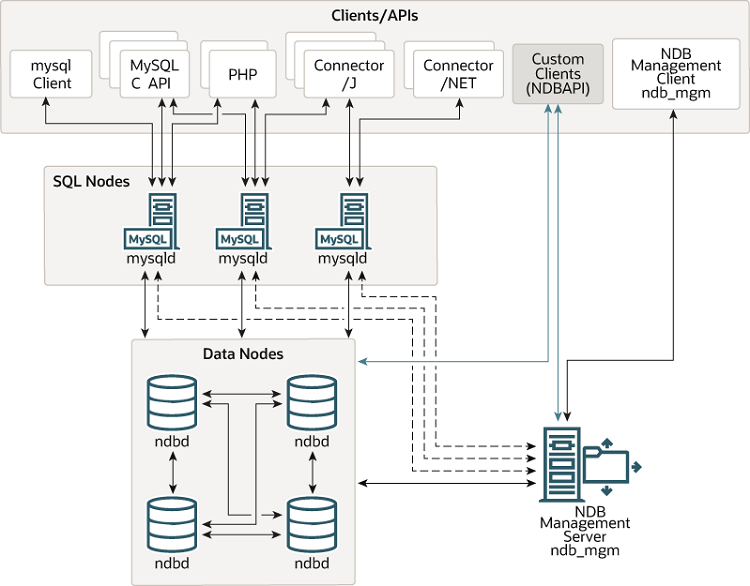
- SQL Node: SQL节点就是传统的MySQL server,包括NDB/Cluster存储引擎。SQL节点处理所有的SQL请求,解析,优化和查询缓存。应用一般是与SQL节点通讯。
- Data Node: 即NDB集群组件。数据节点组成data node group,它的作用主要是存储数据,同时还负责:
- 事务协调
- 记录锁 (record level locking)
- Failover
- Fail-back
- 实现两阶段提交协议
- Management Node: 管理节点主要负责MySQL集群配置和管理,同时是split-brain的仲裁者。
优点
- 高可用性:官方数据是99.999%。
- 高可扩展性:自动sharding,透明分片
- 数据一致性:同步复制+两阶段提交保证数据一致性。
- 只能使用NDB存储引擎。如果使用InnoDB存储引擎,那么无法利用MySQL Cluster的优势。
- 主要体现在事务处理 Limits Relating to Transaction Handling in MySQL Cluster
- 事务隔离级别: NDB只支持READ COMMITTED隔离级别。Differences Between the NDB and InnoDB Storage Engines
- 回滚:不支持partial transactions, and no partial rollbacks of transactions. A duplicate key or similar error causes the entire transaction to be rolled back.
- 不支持大事务:
- etc.
- 主要体现在事务处理 Limits Relating to Transaction Handling in MySQL Cluster
- 从MySQL升级到MySQL集群,对业务并非完全透明,可能需要修改schema和Sql queries。
- 不支持分布式锁,可能会引起脑裂问题(split brain issues)。
- 对BLOB和TEXT字段的支持不友好
- Unsupported or Missing Features in MySQL Cluster
- Index prefixes
- Savepoints and rollbacks
- Durability of commits
- Replication
- 不支持Statement-Based复制方式,支持ROW或者MIXED。
- 不支持GTID
- 存储限制Limitations Relating to MySQL Cluster Disk Data Storage
- 网络通讯严重,分区容忍性差,容易脑裂。
- 短板效应,集群的吞吐率取决于最差的节点。
总结
MySQL Cluster要实现完全冗余和容错,至少需要4台物理主机,其中两个为管理节点。MySQL Cluster使用并不是那么广泛,除了自身架构因素、使用诸多限制之外,另一个重要的原因是其安 装配置管理相对复杂繁琐,总共有几十个操作步骤,需要 DBA 花费几个小时才能搭建戒完成。重启 MySQL Cluster 数捤库的管理操作之前需要执行46个手动命令,需要耗费 DBA 2.5 小时的时闱,而依靠 MySQL Cluster Manager 只需要一个命令就可以完成,但 MySQL Cluster Manager 仅作为商用 MySQL Cluster 运营商级版本(CGE)数据库的一部分提供,需要购买。 所以不推荐使用。
2. Percona XtraDB Cluster(PXC, uses Galera cluster)

与MySQL Cluster实现上的不同 About Percona XtraDB Cluster
- 集群中每一个节点都是普通的MySQL/Percona Server,这意味着你可以把现存的MySQL/Percona Server直接接入集群,或者从集群中拎出来作为普通的MySQL服务。
- 每个节点拥有所有的数据,这意味着节点的数据完全对等,任何查询都可以在本地完成。同时也意味着数据的高度冗余,对写扩展(write scalling)并不是很友好。
- 同步复制,高度一致性
- 多master复制,任何节点都可以读写
- 并发复制 (Parallel applying events on slave. Real “parallel replication”)
- Automatic node provisioning.
- 数据一致性
- 只支持InnoDB存储引擎(包括XtraDB引擎)的复制
- 不支持LOCK/UNLOCK TABLES, GET_LOCK(), RELESE_LOCK()等 锁 语句或者函数
- 短板效应,集群的吞吐率取决于最差的节点。
- …
总体来说,Percona XtraDB Cluster比MySQL Cluster NDB要简单易用一些,归根于他对等节点的设计,同时使用了XTraDB作为存储引擎。所以相对来说对应用要透明很多。
3. MariaDB Galera Cluster
跟Percona XtranDB Cluster一样,MariaDB Galera Cluster也是一个同步多master MariaDB集群 (synchronous multi-master cluster for MariaDB),同样只支持XtraDB/InnoDB存储引擎。
- 同步复制,高度一致性
- 多master复制,任何节点都可以读写(Active-active multi-master topology)
- 并发复制 (True parallel replication, on row level)
- Automatic membership control, failed nodes drop from the cluster; Automatic node joining
- 数据一致性
- Direct client connections, native MariaDB look & fee
- 只支持InnoDB存储引擎(包括XtraDB引擎)的复制
- 不支持LOCK/UNLOCK TABLES, GET_LOCK(), RELESE_LOCK()等 锁 语句或者函数
- 短板效应,集群的吞吐率取决于最差的节点。
- …
对比PXC和MGC,可以发现两者基本都是一样的。
MySQL集群管理平台
现在已经有一些商业的或者开源的MySQL集群管理平台可以简化整个MySQL 部署,管理,监控,和扩容操作。
- ClusterControl:商业
- MySQL based cluster:Galera Cluster for MySQL, Percona XtraDB Cluster, MariaDB Galera Cluster, MySQL Cluster and MySQL Replication
- MongoDB clusters:MongoDB Sharded Cluster, MongoDB Replica Set and TokuMX
- Percona Toolkit for MySQL
- a collection of advanced open source command-line tools
- supports Percona Server, MySQL and MariaDB and works best with Percona Server and other Percona products.
数据库代理/中间件介绍
一般来说,我们引入数据库代理/中间件,来解决下面几个问题:
- 透明:屏蔽底层复杂的部署情况(分库分表, 复制拓扑结构, 集群, etc.),提供单一服务访问和抽象;增加减少机器不需要修改上层应用
- 负载均衡 (load balancing and fault tolerance) & 读写分离
- failover:后端服务监控,摘除或者切换
- 连接池
这些中间件一般有两种部署(实现)模式:
- Client模式
- Server模式
下面是常见的中间件:
1、通用负载均衡器:
- LVS + keepalived
- Keepalived is open-source routing software that provides load-balancing via LVS (Linux Virtual Server) and high-availability via VRRP (Virtual Router Redundancy Protocol).
- Multi-Master MySQL With Percona And Keepalived
- nginx 1.9+ (–with-stream)
- 本质上是一个反向代理服务器(静态资源服务器),可用于后端负载均衡(HTTP/TCP)
- MySQL High Availability with NGINX Plus and Galera Cluster
- 开源版最大的问题是不支持高级backend health checks,Github上有一些第三方实现,需要源码编译和充分自测。
- HAProxy
- 非常类似于Nginx,但是专注于负载均衡。可以监听多个端口,有backup upstream的概念。(不同于Nginx,HAProxy的监控状态是由心跳检测:
check backup,所以相对靠谱一些) - 可以心跳监控后端server可用性,但是只是简单的端口监控。
- Setup MariaDB Enterprise Cluster, part 3: Setup HA Proxy Load Balancer with Read and Write Pools
- 非常类似于Nginx,但是专注于负载均衡。可以监听多个端口,有backup upstream的概念。(不同于Nginx,HAProxy的监控状态是由心跳检测:
2、SQL-aware负载均衡器
- MySQL proxy
- MySQL-Proxy是个进展非常缓慢的开源项目,目前还只有0.8.5 alpha版本,并且已经停止维护和开发了。
- 依赖于lua脚本实现一些逻辑(比如分库分表路由)
- MySQL Proxy is not GA, and is not recommended for Production use. We recommend MySQL Router for production use.
- MySQL Router
- Server模式
- 只支持简单的连接重定向路由 (simple redirect connection routing),因为需要应用出错重试。
- 支持读写分离
- MaxScale
- 可插拔的插件设计架构,可以灵活定制。
- 有五种类型的插件:
- Authentication Plugin
- Protocol Plugin
- Monitoring Plugin: 支持复制监控和集群监控
- Router Plugin: 支持多种路由策略(Connection based, Statement based,Schema based..)
- Filter Plugin
- 自动检测master failure,调用外部Shell脚本来修复拓扑结构(一般委托给 MariaDB Replication Manager(MRM),也可以是MHA,etc.),保证这一切对应用透明。
- MaxScale 1.3.0 开始支持 option substitution for failover,外部Shell脚本不是必须的了。
- Amoeba
- 2008年开源的数据库服务端代理软件,基于Java开发
- 具有负载均衡、高可用性、sql过滤、读写分离、数据切片、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。
- 具有如下限制。
- 不支持failover(没有backup概念,没有自动拓扑结构调整)
- Cobar
- 阿里巴巴开源的分布式数据库中间件
- 支持分库(不支持分表)
- 不支持读写分离
- 有主备概念,采用配置的心跳探测语句对后端连接的MySQL进行心跳检测,判断MySQL运行状况,一旦运行出现异常,Cobar可以自动切换到备机工作。如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
- Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步。
- MyCat
- 基于Cobar的二次开发,号称国内最活跃的、性能最好的开源数据库中间件
- Cobar支持的都支持;同时做了一些增强(全局自增主键,支持多种数据库,支持分表,支持Galera集群,本身基于ZK做集群实现HA,等)
- TDDL(Taobao Distributed Data Layer)
- 淘宝开源的分布式数据库中间件。一个基于集中式配置的jdbc datasource实现,貌似是唯一的Client模式数据库中间件。
- 支持数据库主备和动态切换,带权重的读写分离,集中式数据源信息管理和动态变更,等功能。
- 依赖diamond配置中心
- 复杂度相对较高,当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
单纯的replication failover工具:
- MMM。HA: 99%
- MHA。HA: 99.9%
- PRM 貌似只支持到 MySQL 5.6,不支持最新的MySQL 5.7。
- MySQL Fabric
- Orchestrator
- MariaDB Replication Manager (MRM) 只支持MariaDB with GTID based replication topologies。
但是前面也提到过,这些工具只是改变MySQL的复制拓扑结构,还需要使用其他工具来进行IP address takeover。High Availability without Pacemaker Workaround。常用的IP Address Takeover工具有:
- Heartbeat + Cluster Resource Manager(CRM)
- Corosync + Pacemaker
- Keepalived + VIP/VRRP
- VRRP协议的开源实现。比前两者使用要简单很多,一般用于hot-standby场景。但是因为没有引入CRM工具,所以不大适合做一些比较负责的资源处理。
- Configuring Simple Virtual IP Address Failover Using Keepalived
- 支持自定义检查脚本
- High Availability Support Based on keepalived 挺详细的一篇文章
另一种做法是使用上面提到的数据库中间件或者Proxy对应用保持透明,如HAProxy,Cobar。
这些replication failover工具一般会允许你调用某个外部脚本做一些实情,比如MHA有个选项可以让你调用一个外部脚本来inactivate/activate writer IP address,通过在配置文件中配置master_ip_failover_script配置项。
另外还需要特别注意这些工具对MySQL版本和配置的要求:
- MySQL or MariaDB,比如MRM只支持MariaDB;MHA、PRM等不支持 MariaDB GTID based replication topologies, MySQL Fabric要求MySQL 5.6.x+, etc.
- Replication methods (statement and row based replication)
- supporting GTID?
- etc.
NOTES && TIPS
1、不同于前面说的专门针对复制拓扑结构的failover工具,像MMM, MHA, PRM, MySQL Fabric, Orchestrator, MariaDB Replication Manager (MRM),后者只是做master故障failover(主要是拓扑结构调整),并不提供负载均衡和对应用透明。负载均衡器更关注的是负载均衡和代理。所以在故障failover这块,负载均衡器要显得弱智一些。比如说故障检测,基本上所有的负载均衡器的判断方式都是是——不能查询某个backend server,然后可能有个max_fails和fail_times的参数控制一下,但是本质上就是转发请求失败。但是“连接不上master”退出master挂掉了,这个逻辑还是过于简单。
关于这个可以参考一下Orchestrator作者写的这篇文章 Thoughts on MaxScale automated failover (and Orchestrator),对MaxScale和Orchestrator做了比较详尽的对比,很深入。
2、为了避免代理/中间件单点,一般采用集群部署,前面使用 VIP+ LVS 做负载均衡,或者 keepalived + VIP浮动功能。其实相当于解决了一个比较复杂的HA问题(有状态的HA),同时引入了一个相对简单的HA问题(无状态的HA问题),哈哈。。。
业界HA方案
基本上都是Relication+Sharding方式:
- Flickr: 跟Pinterest一样,sharding
- 淘宝:从TDDL可以看出他们现在还是使用Replication + Sharding方式
- 美图:Replication+ Sharding方式
未来的MySQL:
参考文章和推荐阅读
- MySQL Replication failover: Maxscale vs MHA (part 1)
- MySQL Replication failover: Maxscale vs MHA (part 2)
- MySQL Replication failover: Maxscale vs MHA (part 3)
- Database High Availability (DB HA)
- High-availability options for MySQL, October 2013 update
- mysql-master-ha
- High Availability Solutions for the MariaDB and MySQL® Database
- MySQL Replication for High Availability - Tutorial 关于MySQL同步最新最详细的介绍,强烈推荐。
- High Availability Database Tools
- MySQL Server Using InnoDB Compared with MySQL Cluster
- MyCat权威指南 里面有很多HA的介绍。
- MySQL Reference Architectures for Massively Scalable Web Infrastructure
- MYSQL + MHA +keepalive + VIP安装配置(三)–keepalived安装配置
- Using GTID-based Replication for MySQL High Availability 图文并茂,通俗易懂,深入浅出,强烈推荐!