背景
这个分享来自于创新工场人工智能工程院副院长王咏刚给创新工场暑期深度学习训练营 DeeCamp的培训课程的第一节课。(ps:这个训练营太火了,只招生 36 名,总共有 1000 多计算机专业同学报名,同学们来自 CMU、北大、清华、交大等最好的大学),后续会给大家讲《TensorFlow 实战》、《自然语言处理》、《机器视觉》、《无人驾驶实战》等框架和算法方向的课。
课件分享:AI 基础架构——从大数据到深度学习
下面是我给创新工场暑期深度学习训练营 DeeCamp 讲的时长两小时的内部培训课程《AI 基础架构:从大数据到深度学习》的全部课件。全部讲解内容过于细致、冗长,这里就不分享了。对每页课件,我在下面只做一个简单的文字概括。
注:以下这个课件的讲解思路主要是用 Google 的架构发展经验,对大数据到机器学习再到近年来的深度学习相关的典型系统架构,做一个原理和发展方向上的梳理。因为时间关系,这个课件和讲解比较偏重 offline 的大数据和机器学习流程,对 online serving 的架构讨论较少——这当然不代表 online serving 不重要,只是必须有所取舍而已。

这个 slides 是最近三四年的时间里,逐渐更新、逐渐补充形成的。最早是英文讲的,所以后续补充的内容就都是英文的(英文水平有限,错漏难免)。

如何认识 AI 基础架构的问题,直到现在,还是一个见仁见智的领域。这里提的,主要是个人的理解和经验,不代表任何学术流派或主流观点。
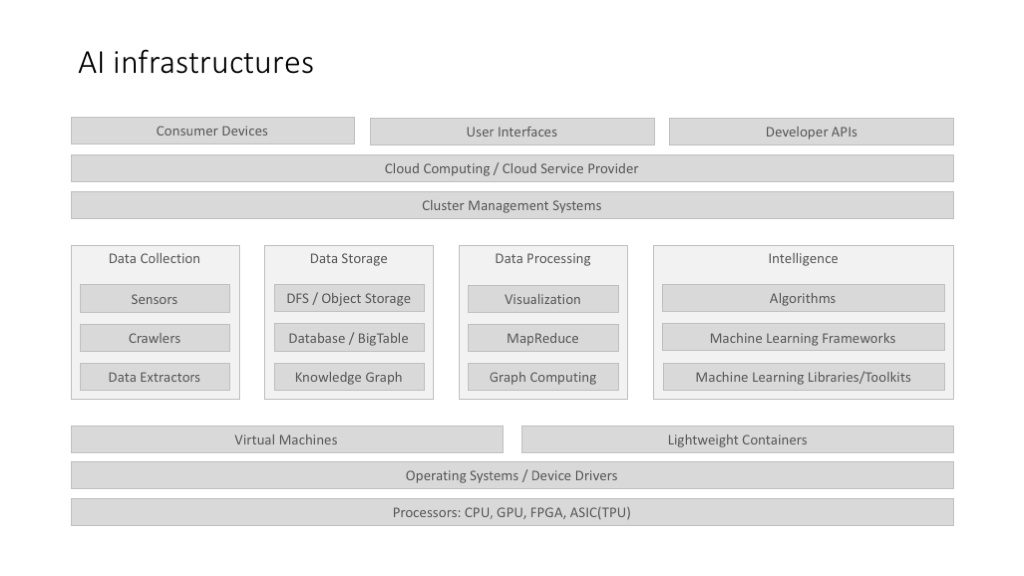
上面这个图,不是说所有 AI 系统/应用都有这样的 full stack,而是说,当我们考虑 AI 基础架构的时候,我们应该考虑哪些因素。而且,更重要的一点,上面这个架构图,是把大数据架构,和机器学习架构结合在一起来讨论的。
架构图的上层,比较强调云服务的架构,这个主要是因为,目前的 AI 应用有很大一部分是面向 B 端用户的,这里涉及到私有云的部署、企业云的部署等云计算相关方案。
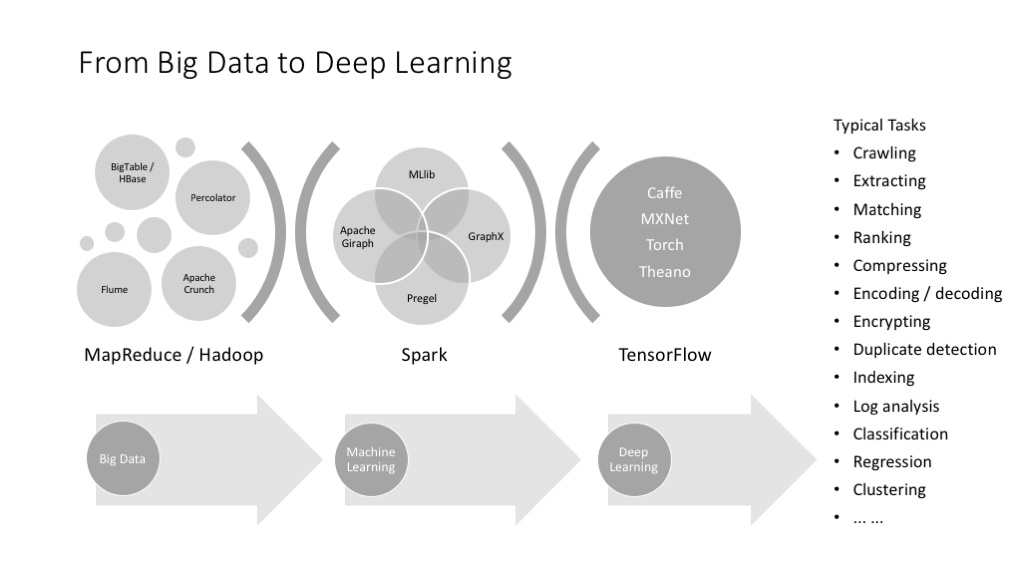
上面这个图把机器学习和深度学习并列,这在概念上不太好,因为深度学习是机器学习的一部分,但从实践上讲,又只好这样,因为深度学习已经枝繁叶茂,不得不单提出来介绍了。

先从虚拟化讲起,这个是大数据、AI 甚至所有架构的基础(当然不是说所有应用都需要虚拟化,而是说虚拟化目前已经太普遍了)。
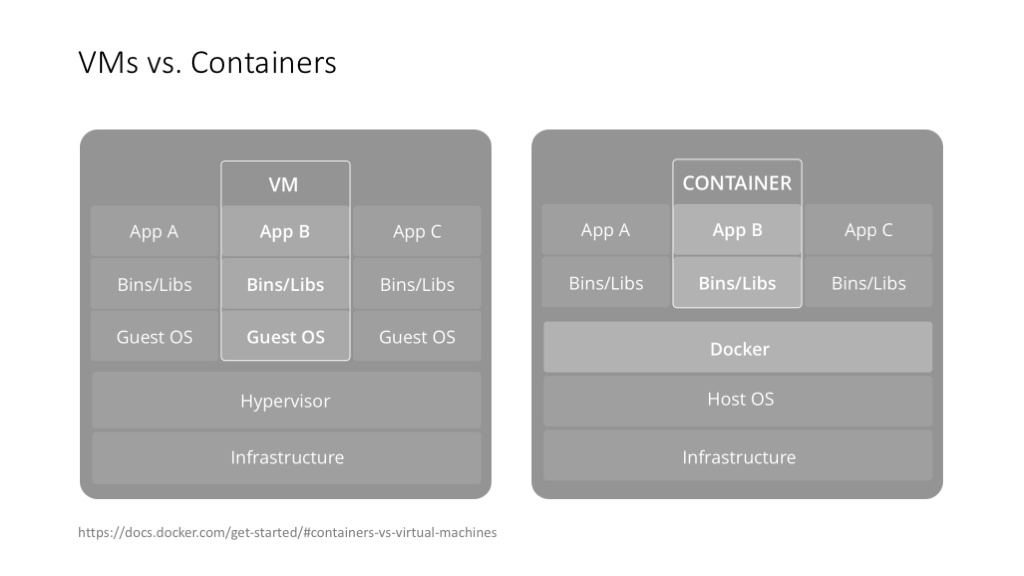
这个是 Docker 自己画的 VM vs. Container 的图。我跟 DeeCamp 学员讲这一页的时候,是先从 Linux 的 chroot 命令开始讲起的,然后才讲到轻量级的 container 和重量级的 VM,讲到应用隔离、接口隔离、系统隔离、资源隔离等概念。
说明
1、chroot: chroot,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以 /,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 / 位置。如果新根下的目录结构和文件准备的够充分,那么一个新的简单的 Linux 系统就可以使用了。这就是百度V2环境(一种在centos4.6上切换到centos6.3的简单粗暴的机制)的基本原理。
2、docker的隔离机制是通过Linux的Namespace和CGroup(Control Groups)实现,具体参见 Docker 核心技术与实现原理。
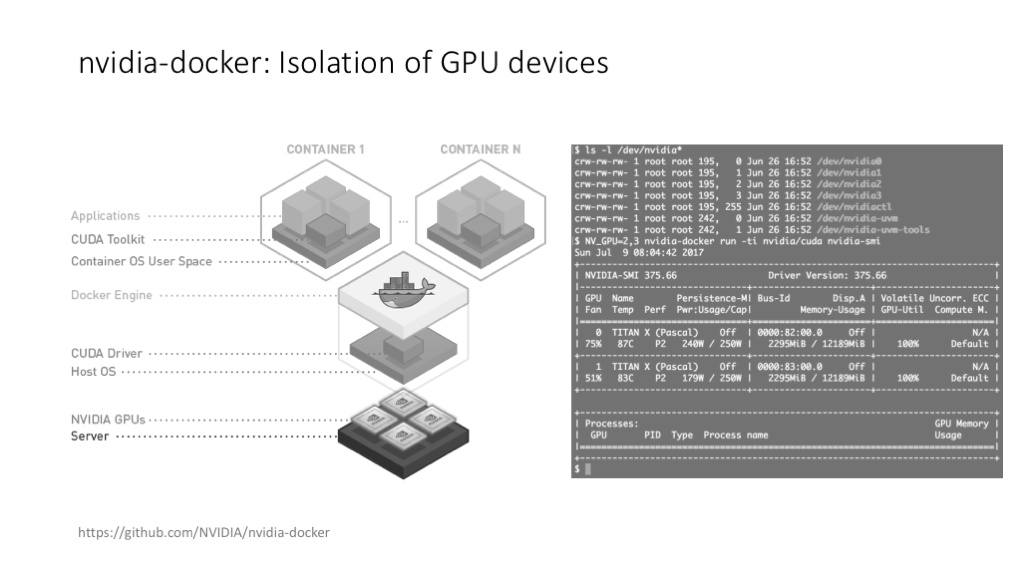
给 DeeCamp 学员展示了一下 docker(严格说是 nvidia-docker)在管理 GPU 资源上的灵活度,在搭建、运行和维护 TensorFlow 环境时为什么比裸的系统方便。
说明
对于nvdia显卡,我们可以使用nvidia-smi命令直接查看显卡的相关信息:
[work@xxxx ~]$ nvidia-smi
Wed Sep 27 15:30:29 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.48 Driver Version: 367.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Quadro K1200 On | 0000:05:00.0 Off | N/A |
| 39% 35C P8 1W / 35W | 0MiB / 4041MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
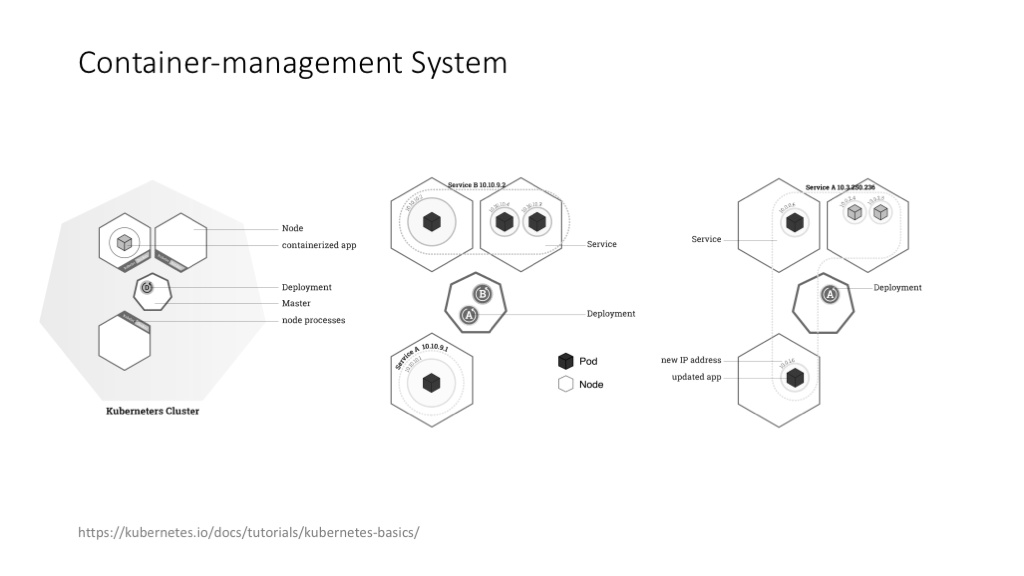
严格说,Kubernetes 现在的应用远没有 Docker 那么普及,但很多做机器学习、深度学习的公司,包括创业公司,都比较需要类似的 container-management system,需要自动化的集群管理、任务管理和资源调度。Kubernetes 的设计理念其实代表了 Google 在容器管理、集群管理、任务管理方面的整体思路,特别推荐这个讲背景的文章:Borg, Omega, and Kubernetes
说明 container-management system
docker引入了容器的概念,极大的方便了服务的打包,和提供一个独立隔离的运行环境,但是一个真实的线上应用往往是由很多服务一起协作完成,意味着需要对这些容器进行管理和编排。目前业界主流的开源工具是 Kuberntes。Kubernetes是Google开源的容器集群管理系统。它构建Ddocker技术之上,为容器化的应用提供资源调度、部署运行、服务发现、扩容缩容等整一套功能,本质上可看作是基于容器技术的mini-PaaS平台。

讲大数据架构,我基本上会从 Google 的三架马车(MapReduce、GFS、Bigtable)讲起,尽管这三架马车现在看来都是“老”技术了,但理解这三架马车背后的设计理念,是更好理解所有“现代”架构的一个基础。
说明 谷歌的三套车
- The Google File System: 这是分布式文件系统领域划时代意义的论文,文中的多副本机制、控制流与数据流隔离和追加写模式等概念几乎成为了分布式文件系统领域的标准,其影响之深远通过其5000+的引用就可见一斑了,Apache Hadoop鼎鼎大名的HDFS就是GFS的模仿之作。
- MapReduce: Simplified Data Processing on Large Clusters: 这篇也是Google的大作,通过Map和Reduce两个操作,大大简化了分布式计算的复杂度,使得任何需要的程序员都可以编写分布式计算程序,其中使用到的技术值得我们好好学习:简约而不简单!Hadoop也根据这篇论文做了一个开源的MapReduce。
- Bigtable: A Distributed Storage System for Structured Data: Google在NoSQL领域的分布式表格系统,LSM树的最好使用范例,广泛应用于网页索引存储、YouTube数据管理等业务,Hadoop对应的开源系统叫HBase。
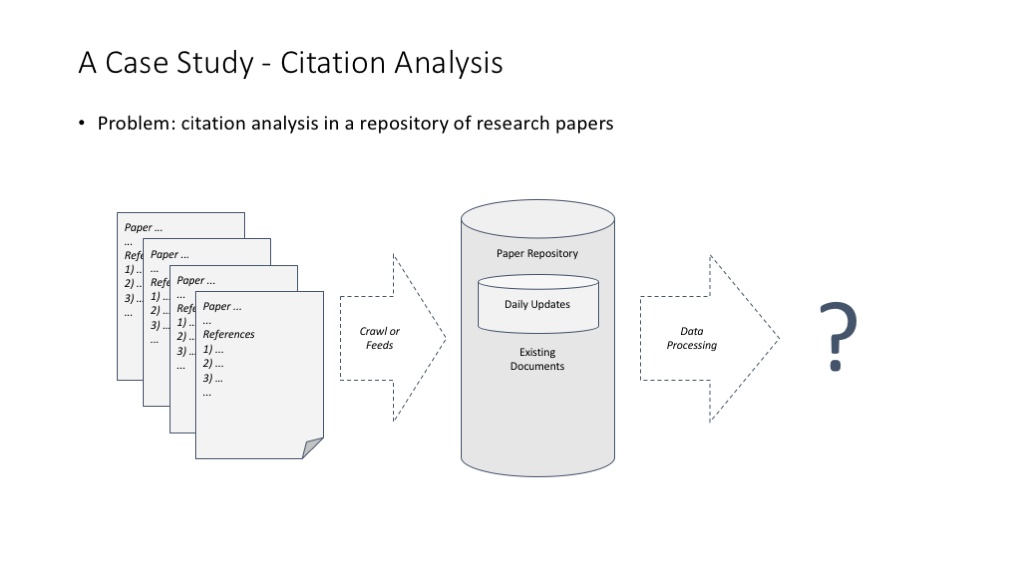
讲 MapReduce 理念特别常用的一个例子,论文引用计数(正向计数和反向计数)问题。
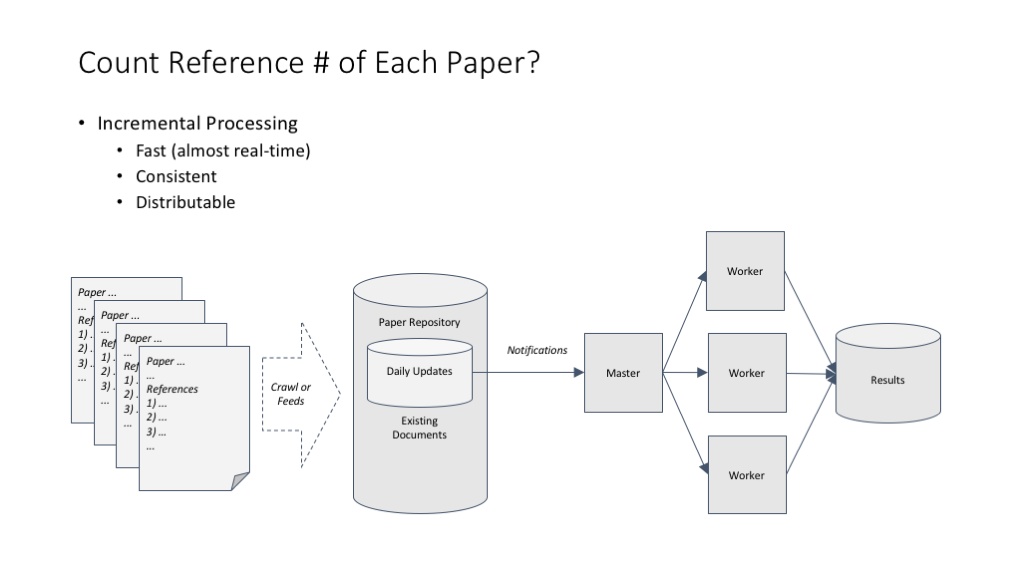
统计一篇论文有多少参考文献,这个超级简单的计算问题在分布式环境中带来两个思考:(1)可以在不用考虑结果一致性的情况下做简单的分布式处理;(2)可以非常快地用增量方式处理数据。
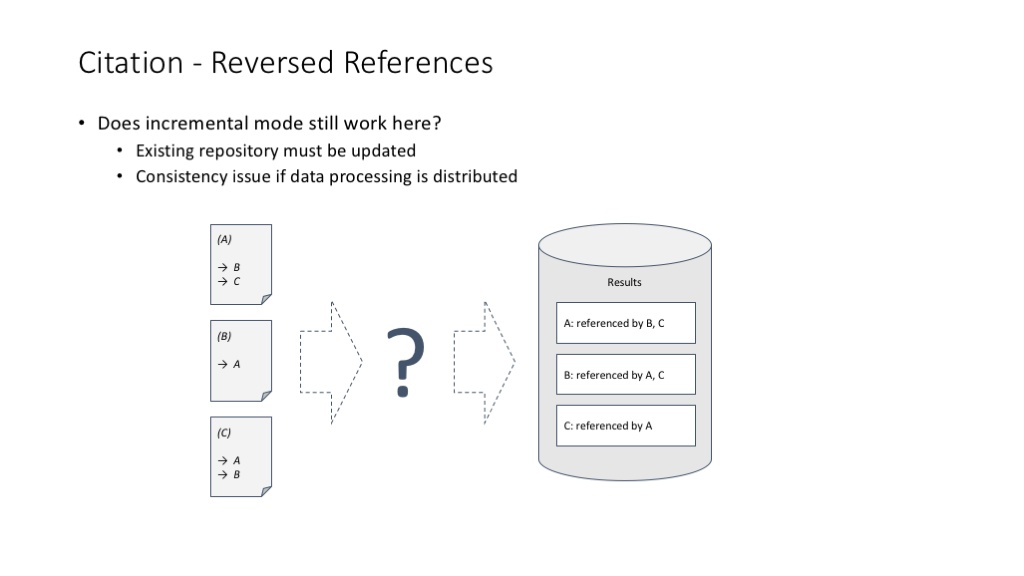
但是,当我们统计一篇文献被多少篇论文引用的时候,这个事情就不那么简单了。这主要带来了一个分布式任务中常见的数据访问一致性问题(我们说的当然不是单线程环境如何解决这个问题啦)。

很久以前我们是用关系型数据库来解决数据访问一致性的问题的,关系型数据库提供的 Transaction 机制在分布式环境中,可以很方便地满足 ACID(Atomicity, Consistency, Isolation, Durability) 的要求。但是,关系型数据库明显不适合解决大规模数据的分布式计算问题。
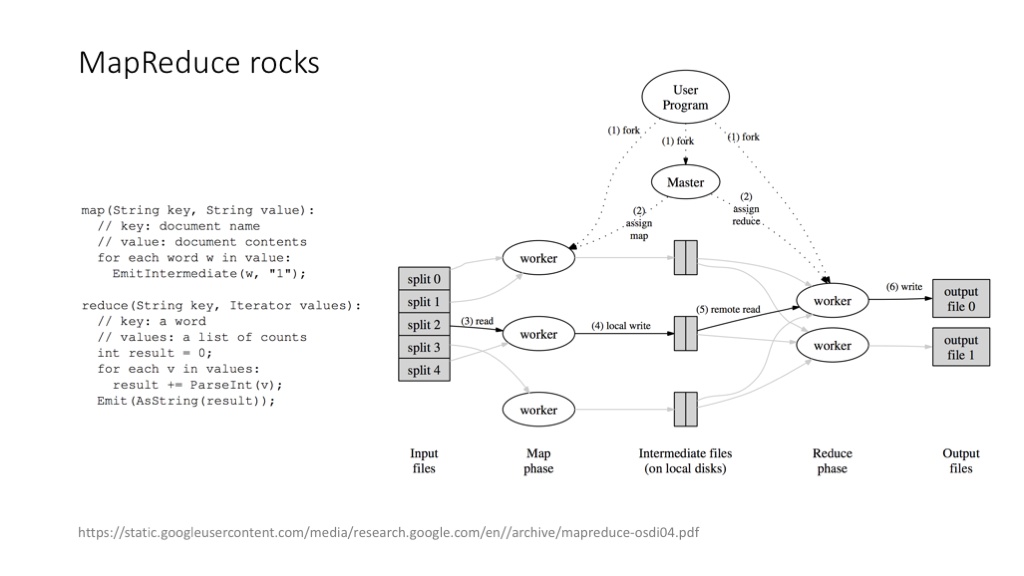
Google 的 MapReduce 解决这个问题的思路非常巧妙,是计算机架构设计历史上绝对的经典案例:MapReduce 把一个可能带来 ACID 困扰的事务计算问题,拆解成 Map 和 Reduce 两个计算阶段,每个单独的计算阶段,都特别适合做分布式处理,而且特别适合做大规模的分布式处理。
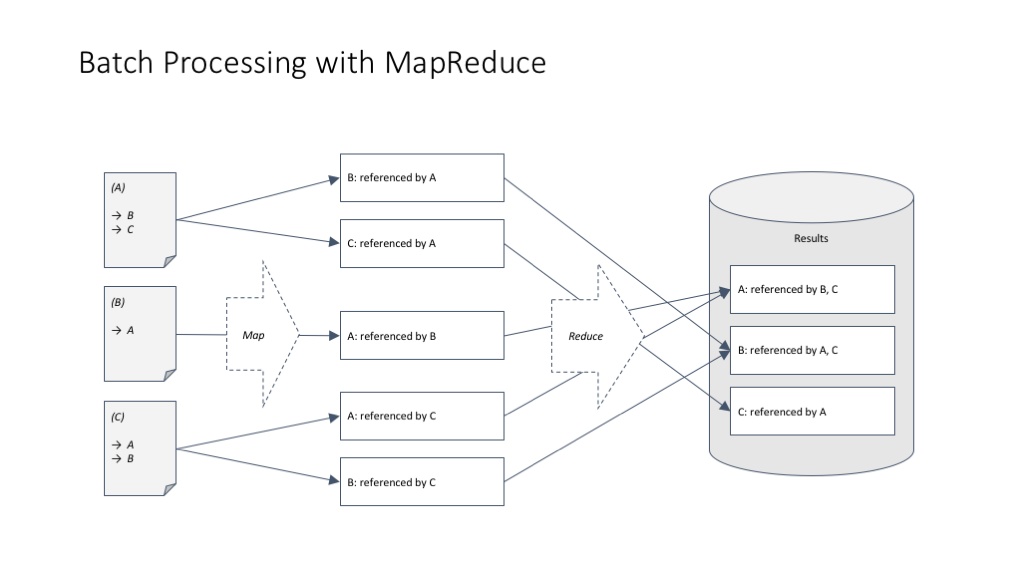
MapReduce 解决引用计数问题的基本框架。
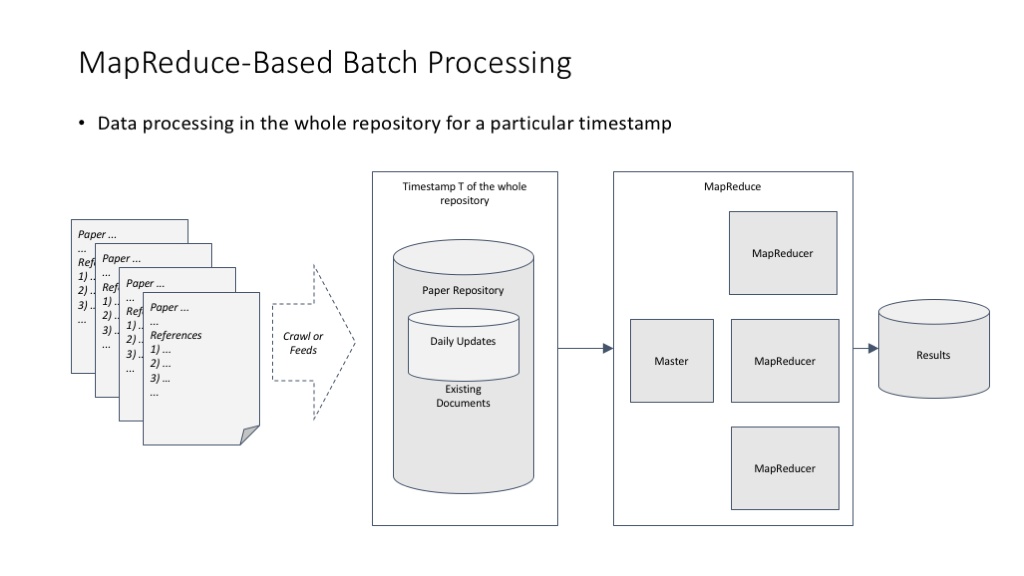
MapReduce 在完美解决分布式计算的同时,其实也带来了一个不大不小的副作用:MapReduce 最适合对数据进行批量处理,而不是那么适合对数据进行增量处理。比如早期 Google 在维护网页索引这件事上,就必须批量处理网页数据,这必然造成一次批量处理的耗时较长。Google 早期的解决方案是把网页按更新频度分成不同的库,每个库使用不同的批量处理周期。
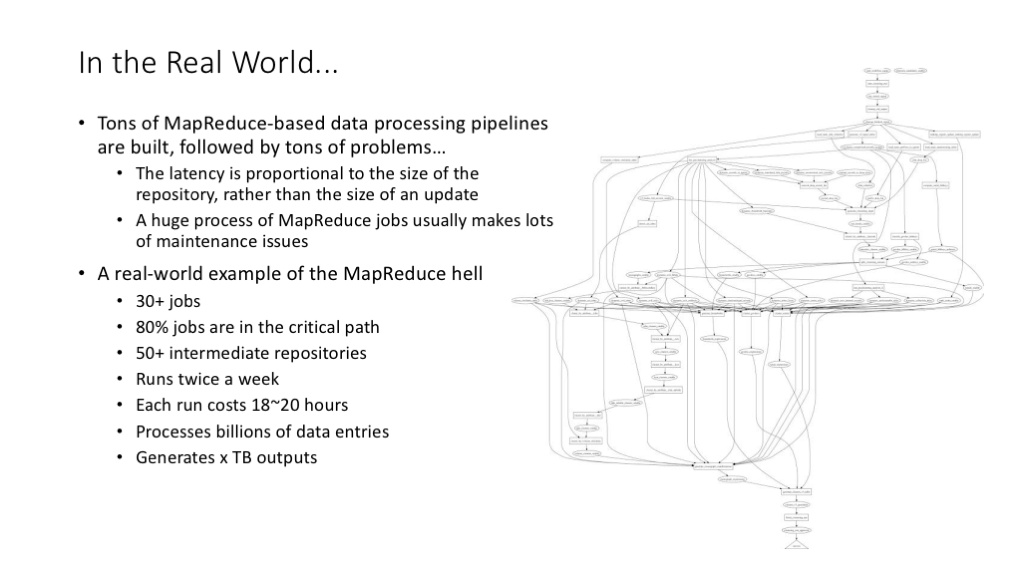
用 MapReduce 带来的另一个问题是,常见的系统性问题,往往是由一大堆 MapReduce 操作链接而成的,这种链接关系往往形成了复杂的工作流,整个工作流的运行周期长,管理维护成本高,关键路径上的一个任务失败就有可能要求整个工作流重新启动。不过这也是 Google 内部大数据处理的典型流程、常见场景。

Flume(FlumeJava: Easy, Efficient Data-Parallel Pipelines)是简化 MapReduce 复杂流程开发、管理和维护的一个好东东。

Apache 有开源版本的 FlumeJava 实现 (Apache Crunch。FlumeJava 把复杂的 Mapper、Reducer 等底层操作,抽象成上层的、比较纯粹的数据模型的操作。PCollection、PTable 这种抽象层,还有基于这些抽象层的相关操作,是大数据处理流程进化道路上的重要一步(在这个角度上,FlumeJava 的思想与 TensorFlow 对于 tensor 以及 tensor 数据流的封装,有异曲同工的地方)。
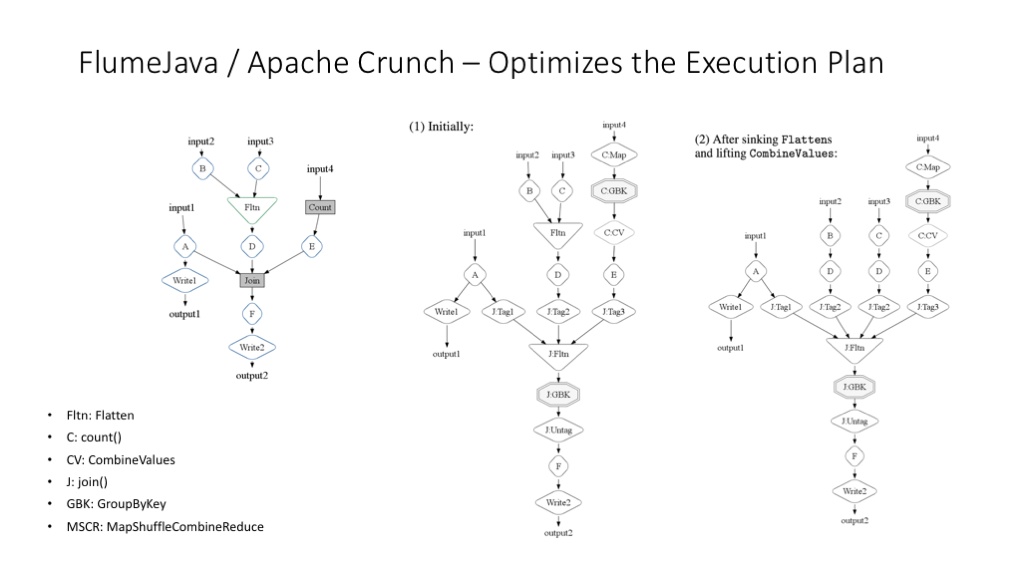
FlumeJava 更重要的功能是可以对 MapReduce 工作流程进行运行时的优化。
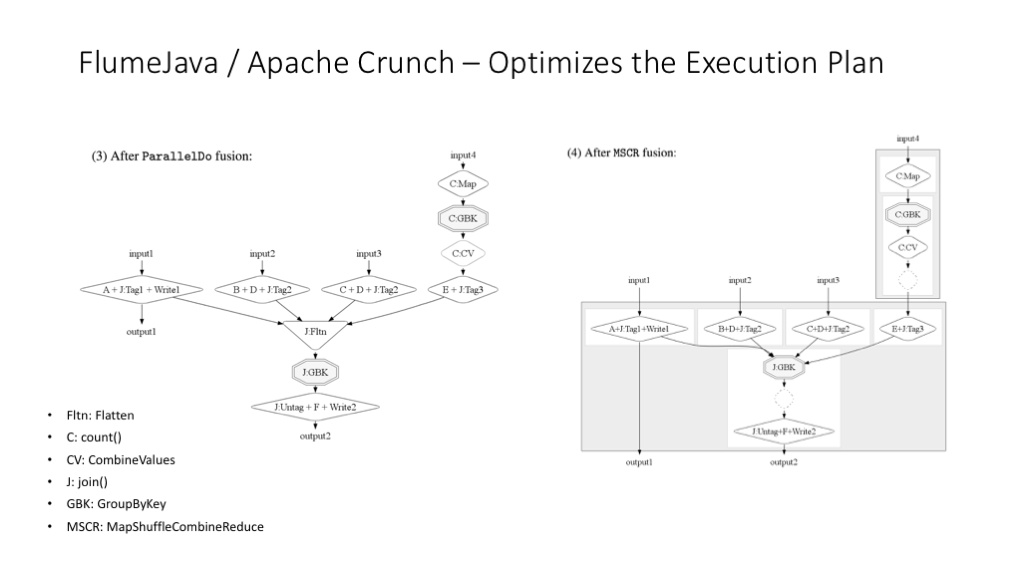
更多关于 FlumeJava 运行时优化的解释图。

FlumeJava 并没有改变 MapReduce 最适合于批处理任务的本质。那么,有没有适合大规模数据增量(甚至实时)处理的基础架构呢?
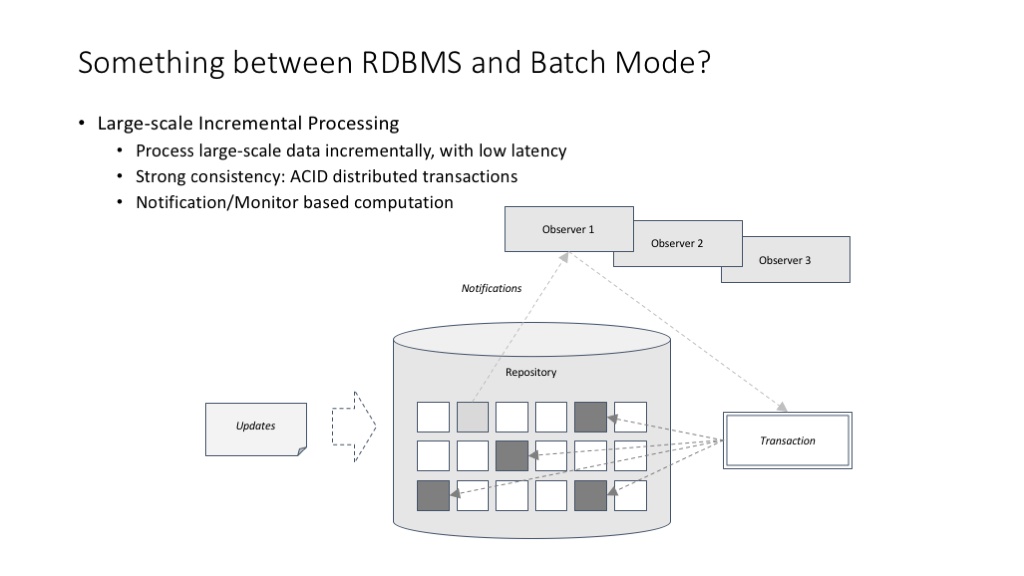
谈到大规模数据增量(甚至实时)处理,我们谈的其实是一个兼具关系型数据库的 transaction 机制,以及 MapReduce 的可扩展性的东西。这样的东西有不同的设计思路,其中一种架构设计思路叫 notification/monitor 模式。
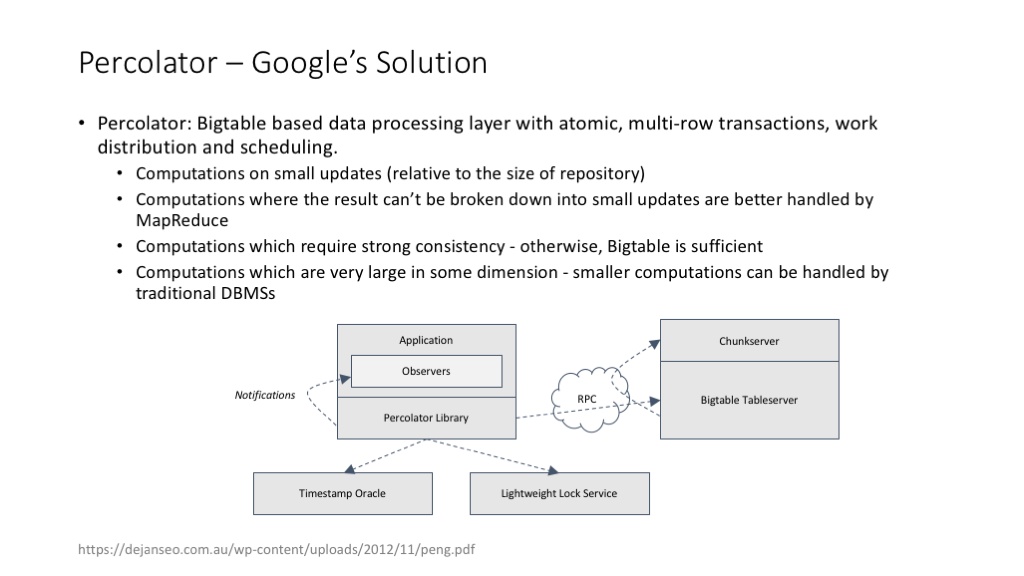
Google percolator 的论文给出了 notification/monitor 模式的一种实现方案。这个方案基于Bigtable,实际上就是在 Bigtable 超靠谱的可扩展性的基础上,增加了一种非常巧妙实现的跨记录的 transaction 机制。

percolator( Google的海量数据增量处理系统)支持类似关系型数据库的 transaction,可以保证同时发生的分布式任务在数据访问和结果产出时的一致性。
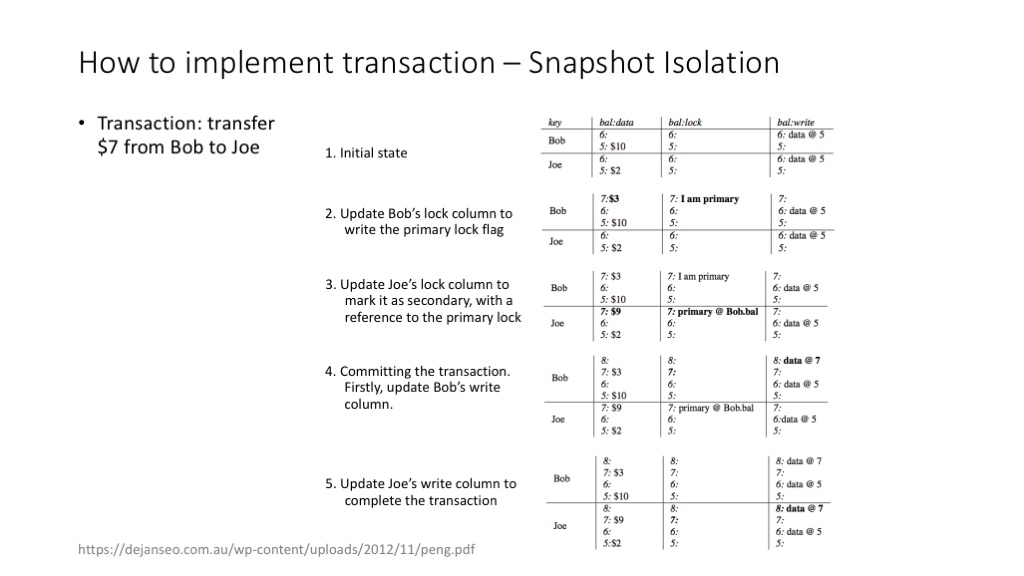
percolator 实现 transaction 的方法:(1)使用 timestamp 隔离不同时间点的操作;(2)使用 write、lock 列实现 transaction 中的锁功能。详细的介绍可以参考 percolator 的 paper。( Large-scale Incremental Processing Using Distributed Transactions and Notifications )
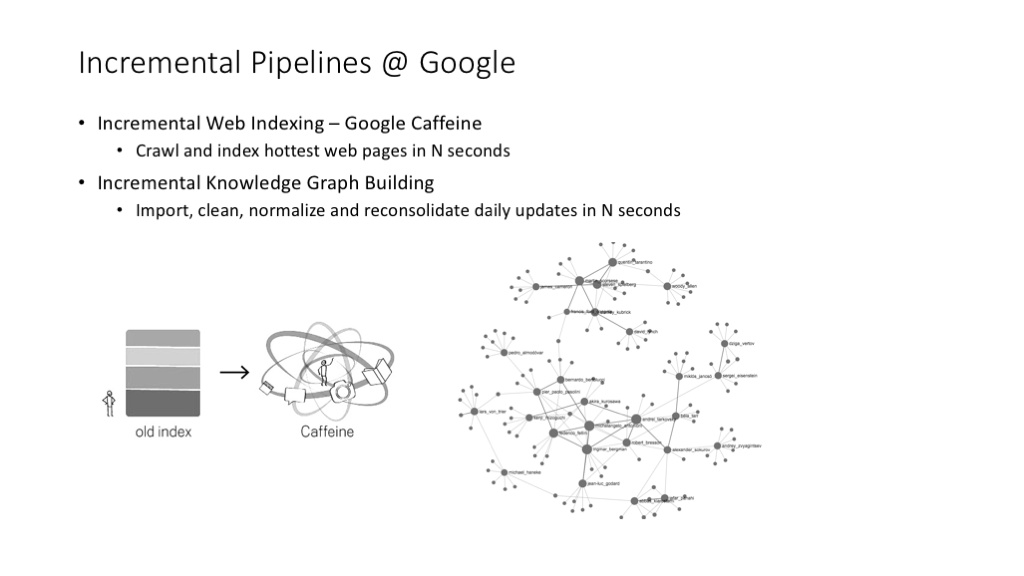
Google 的网页索引流程、Google Knowledge Graph 的创建与更新流程,都已经完成了增量化处理的改造,与以前的批处理系统相比,可以达到非常快(甚至近乎实时)的更新速度。——这个事情发生在几年以前,目前 Google 还在持续对这样的大数据流程进行改造,各种新的大数据处理技术还在不停出现。

大数据流程建立了之后,很自然地就会出现机器学习的需求,需要适应机器学习的系统架构。
说明
王院长在介绍大数据基础架构的时候内容还是过于简略有所缺失的。其实大数据架构是一个非常庞杂的系统和生态(可以参见笔者前面写的一篇文章 大数据平台学习笔记略知一二)
单纯看批量处理引擎就有 Hadoop, Spark, Hive, Impala, Kylin, 而且不得不介绍一下YARN。而(近)实时处理(Real-time Processing)引擎,也没有介绍业界普遍使用的Spark Streaming和Flink。

MapReduce 这种适合批处理流程的系统,通常并不适合于许多复杂的机器学习任务,比如用 MapReduce 来做图的算法,特别是需要多次迭代的算法,就特别耗时、费力。
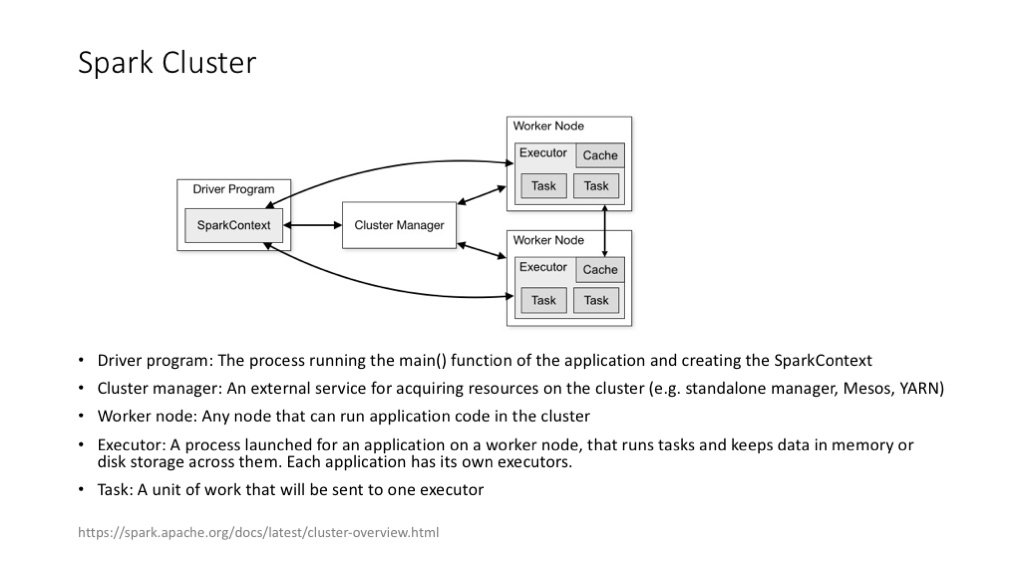
Spark 以及 Spark MLlib 给机器学习提供了更好用的支持框架。Spark 的优势在于支持对 RDD 的高效、多次访问,这几乎是给那些需要多次迭代的机器学习算法量身定做的。
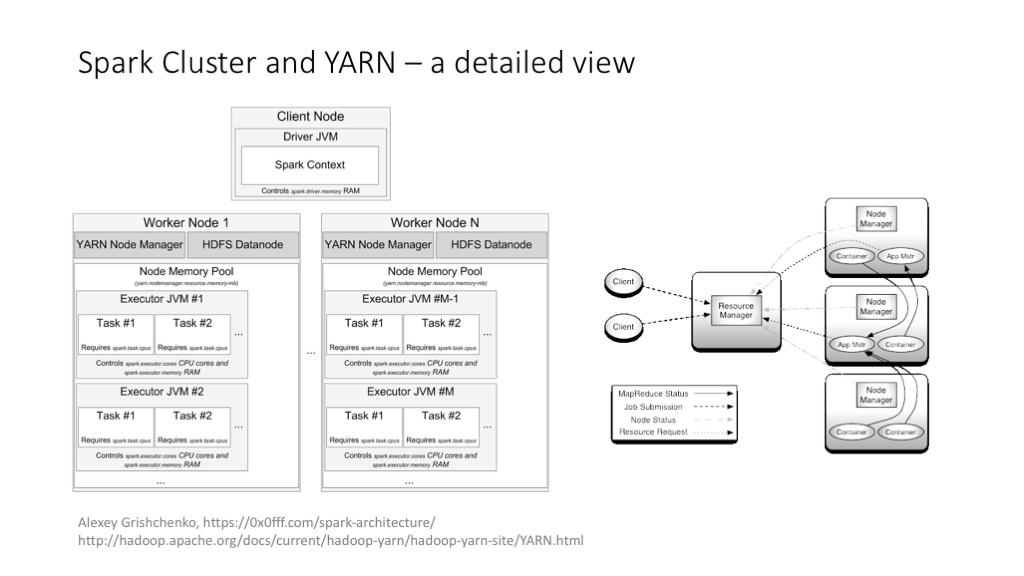
Spark 的集群架构,和 YARN 的集成等。

Google Pregel 的 paper 给出了一种高效完成图计算的思路。
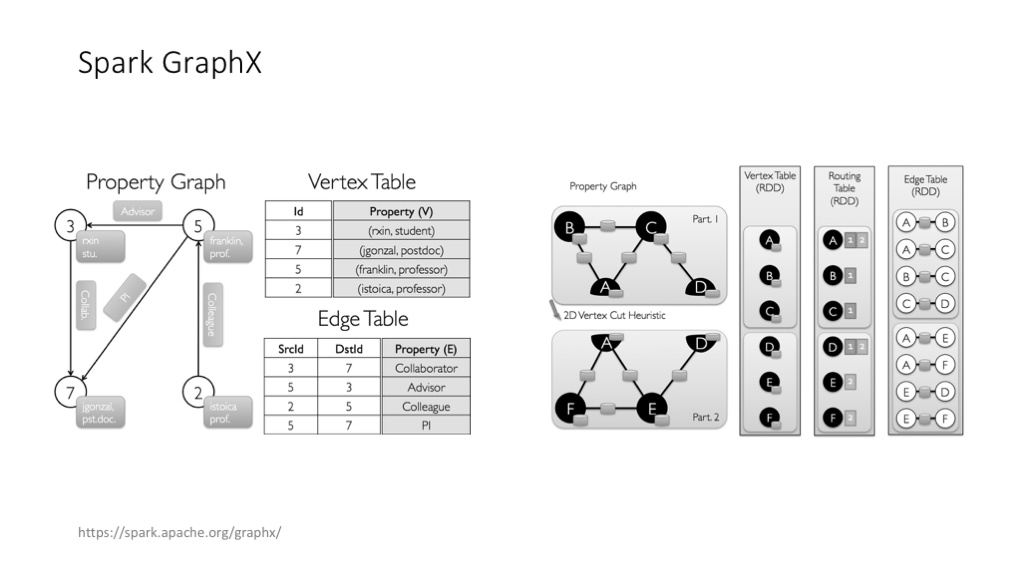
Spark GraphX 也是图计算的好用架构。

深度学习的分布式架构,其实是与大数据的分布式架构一脉相承的。——其实在 Google,Jeff Dean 和他的架构团队,在设计 TensorFlow 的架构时,就在大量使用以往在 MapReduce、Bigtable、Flume 等的实现中积累的经验。
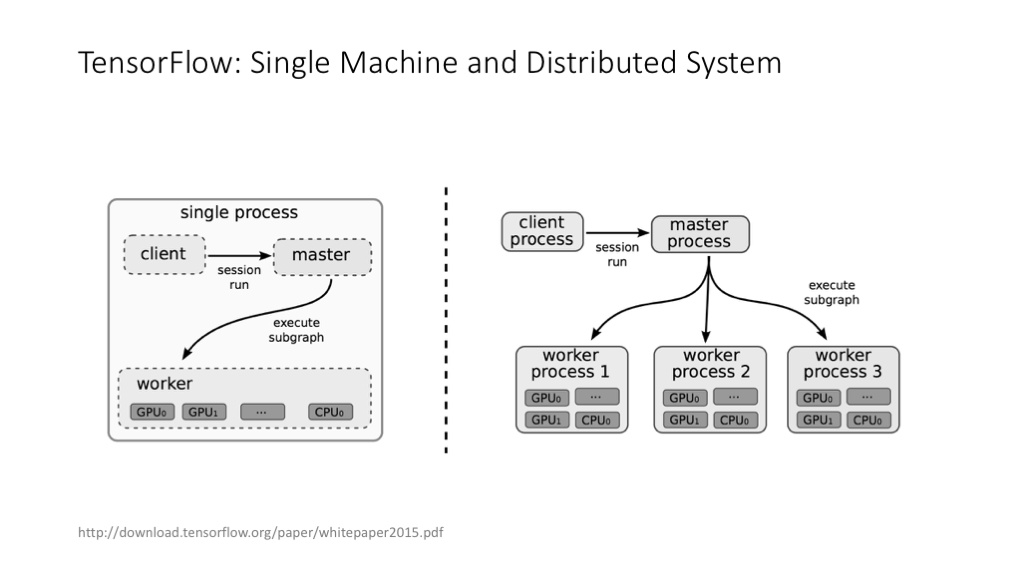
TensorFlow 经典论文中对 TensorFlow 架构的讲解。
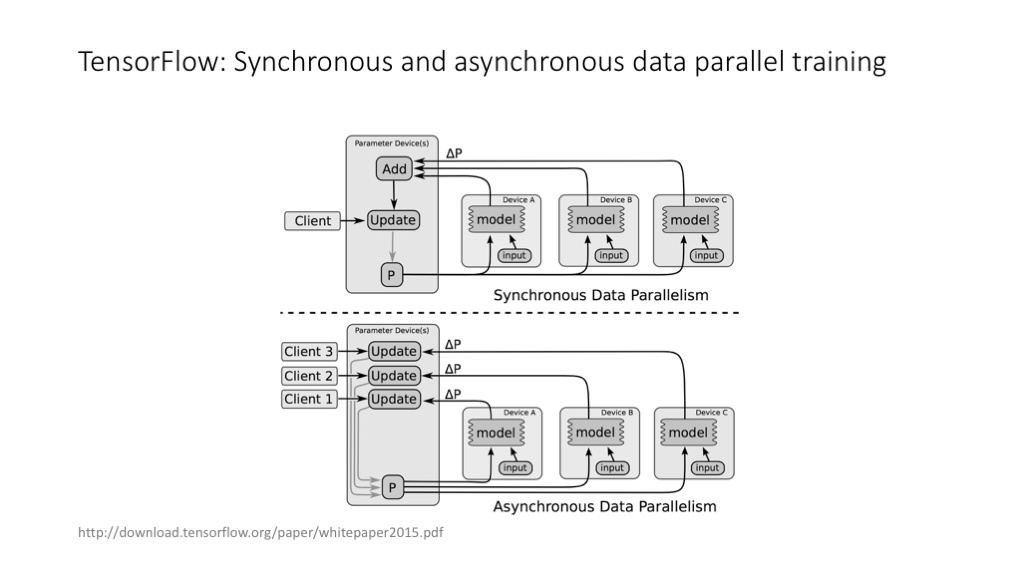
TensorFlow 中的同步训练和异步训练。
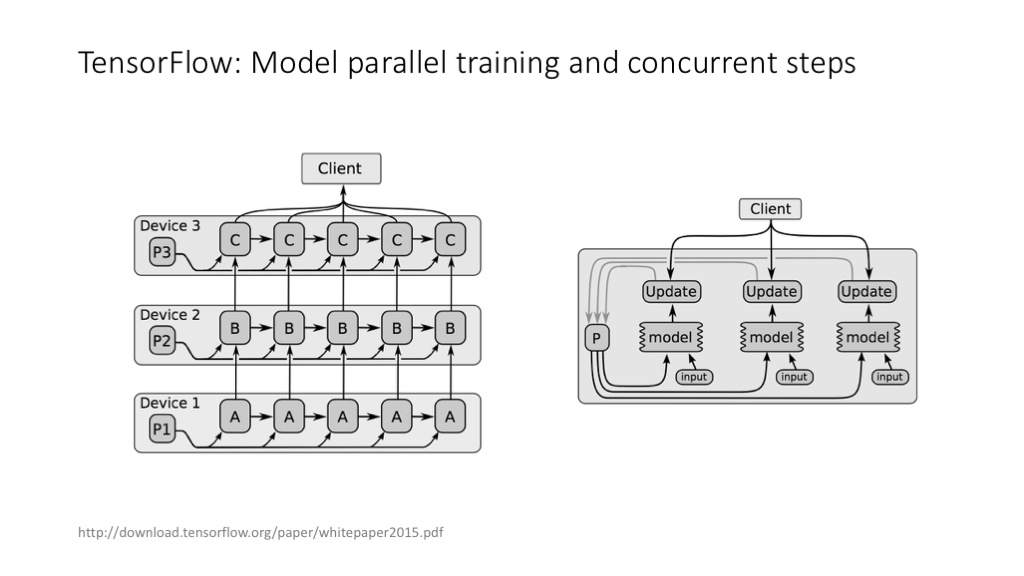
TensorFlow 中的不同的并行策略。

可视化是个与架构有点儿关系,但更像一个 feature 的领域。对机器学习特别是深度学习算法的可视化,未来会变得越来越重要。
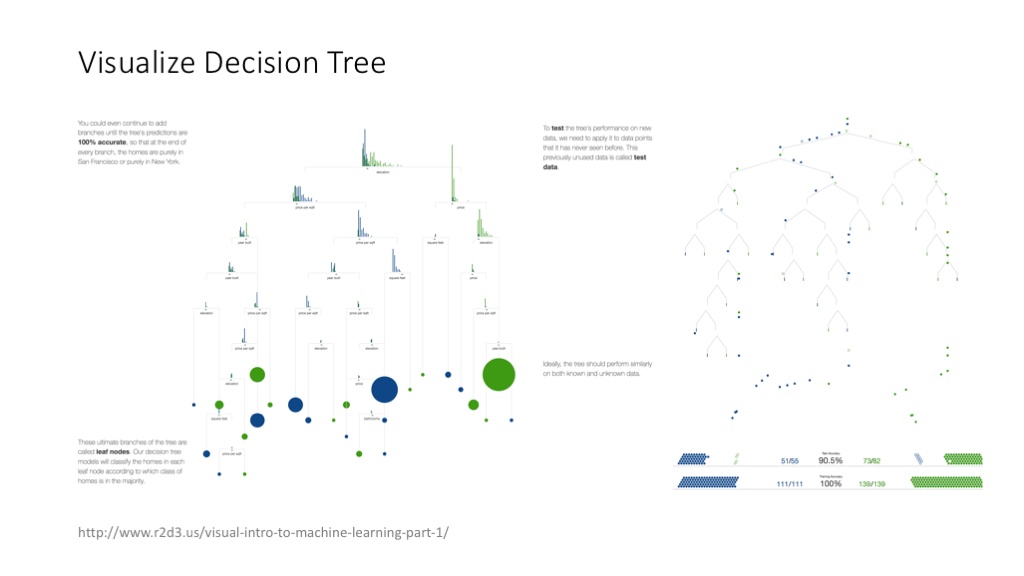
这个对决策树算法进行可视化的网站,非常好玩。
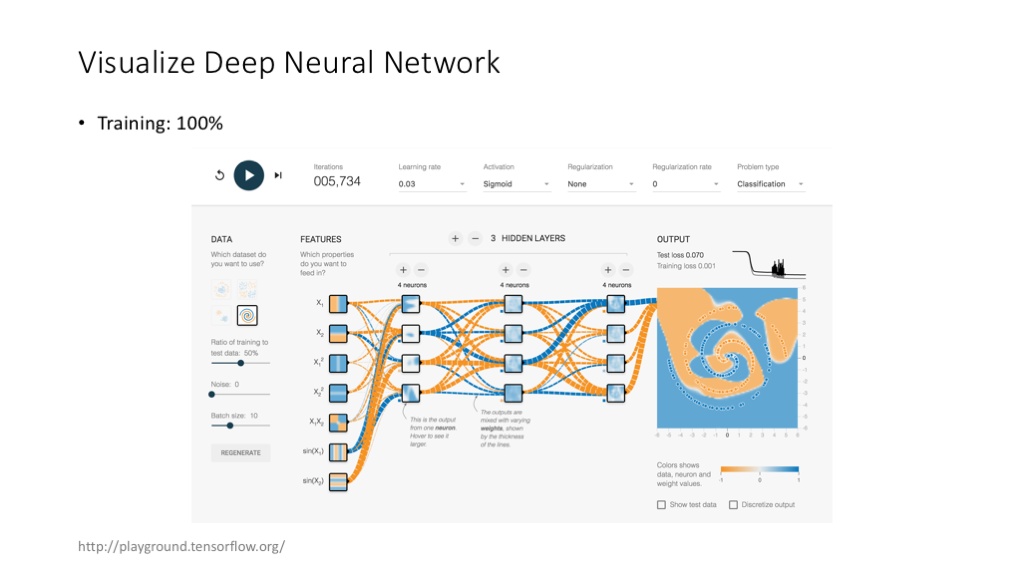
TensorFlow 自己提供的可视化工具,也非常有意思(当然,上图应用属于玩具性质,不是真正意义上,将用户自己的模型可视化的工具)。

有关架构的几篇极其经典的 paper 在这里了。
这里把它文字化和加上链接,方便大家下载阅读:
- MapReduce: Simplified Data Processing on Large Clusters
- FlumeJava: Easy, Efficient Data-Parallel Pipelines
- Large-scale Incremental Processing Using Distributed Transactions and Notifications
- Spark: Cluster Computing with Working Sets
- Pregel: A System for Large-Scale Graph Processing
- TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
参考文章
- 为什么 AI 工程师要懂一点架构?
- 理解 chroot
- Docker 核心技术与实现原理 深入浅出,图文并茂的一篇文章!