最近 国家企业信用信息公示系统 的验证码又升级了。之前是 点按后滑动拼图方式:
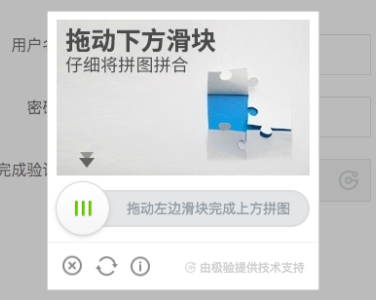
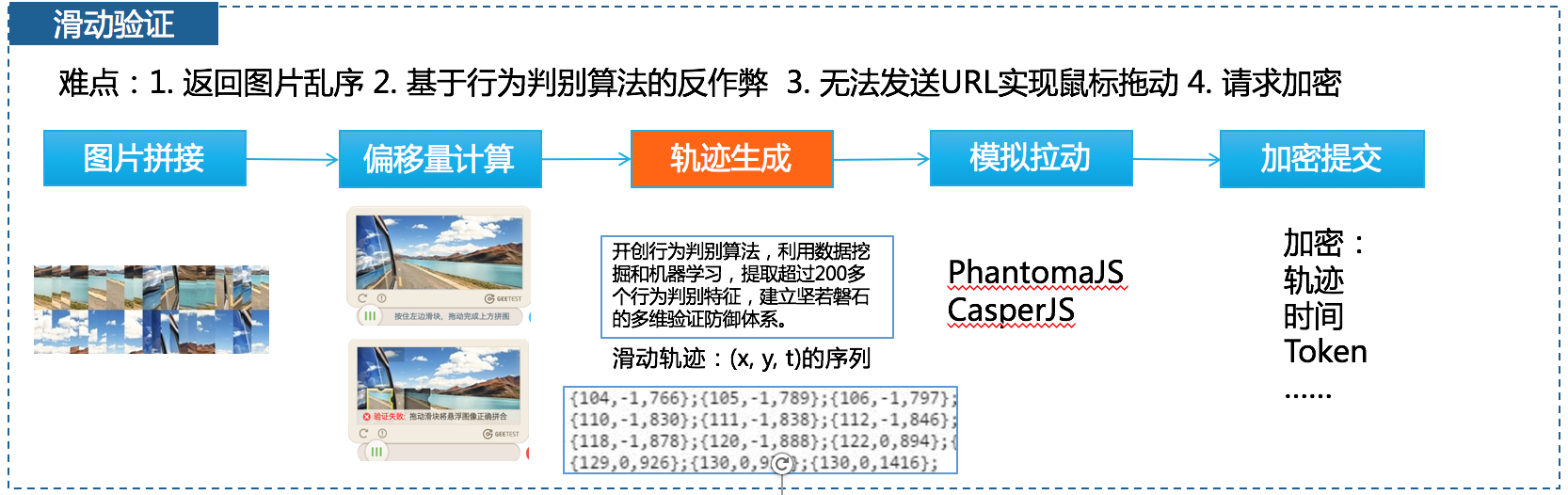
解决方案虽然麻烦,但是偏向于工程架构方面,没有什么算法的东东:
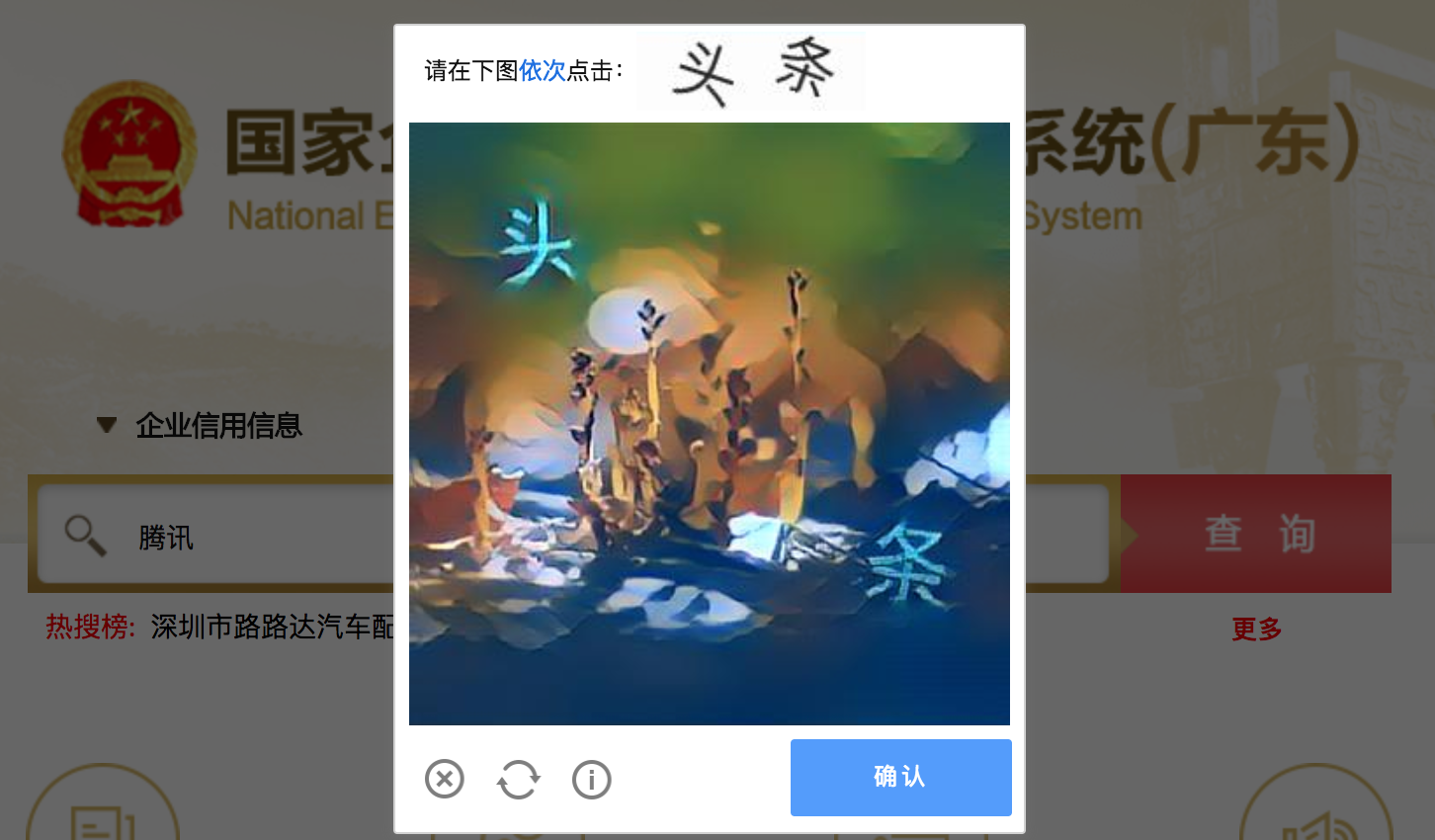
但是最近升级之后新增了一种验证码模式——点按后顺序选字方式:

这个就没办法用纯工程的方式来解决了。必须使用到机器学习的方式了。机器学习的最基本的就是要模型训练,而模型训练就需要样本和标注(有监督学习)。所以首先我们要想办法拿到大量的验证码图片,进行标注和训练。
但是这个验证码要 进入到首页在搜索框输入文字点击搜索按钮 才会出现:
所以我们要能够模拟用户请求进入到首页在搜索框输入文字然后点击搜索按钮,将弹出的验证码图片保存下来。
欣哥一开始负责这个事情,他用CasperJS写了一个脚本模拟这个事情,但是发现根本连首页都进不去,返回错误页面403 forbidden,所以找我帮忙看一下这个事情。
用curl或者chrome inspect网络查看HTTP请求:
curl -A "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36" -b "__jsluid=3a6d5e29aa752ebf04fb7d202af596a6" -e "http://gd.gsxt.gov.cn/index.html" -v http://gd.gsxt.gov.cn/index.html
发现网站返回的并不是正常的页面,而是一段JS:
➜ ~ curl -A "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36" -b "__jsluid=3a6d5e29aa752ebf04fb7d202af596a6" -e "http://gd.gsxt.gov.cn/index.html" -v http://gd.gsxt.gov.cn/index.html
* Trying 112.90.216.65...
* TCP_NODELAY set
* Connected to gd.gsxt.gov.cn (112.90.216.65) port 80 (#0)
> GET /index.html HTTP/1.1
> Host: gd.gsxt.gov.cn
> User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36
> Accept: */*
> Referer: http://gd.gsxt.gov.cn/index.html
> Cookie: __jsluid=3a6d5e29aa752ebf04fb7d202af596a6
>
< HTTP/1.1 521
< Server: nginx
< Date: Fri, 05 Jan 2018 11:31:02 GMT
< Transfer-Encoding: chunked
< Connection: keep-alive
<
<script>var x="cookie@f@parseInt@6@__jsl_clearance@227@OQ@h@DW@1515151862@https@2@12@dc@substr@length@l@Expires@1500@toLowerCase@setTimeout@r@B@location@EV@document@function@for@charAt@replace@FAh@_phantom@window@challenge@D@return@Be@div@__phantomas@match@Tk@0@05@createElement@3@2F@cd@1@qW5@36@captcha@href@var@a@Jan@innerHTML@x@toString@Fri@18@join@while@firstChild@i@31@02@GMT@Path@if@try@addEventListener@catch@e@false@DOMContentLoaded@else@attachEvent@onreadystatechange".replace(/@*$/,"").split("@"),y="49 16=25(){57(30.2a||30.36){};49 43,13='5=a.6|39|';49 2=[25(52){33 52},25(52){33 52;},(25(){49 8=24.40('35');8.51='<4a 48=\\'/\\'>52</4a>';8=8.58.48;49 20=8.37(/10?:\\/\\//)[39];8=8.14(20.15).19();33 25(52){26(49 59=39;59<52.15;59++){52[59]=8.27(52[59])};33 52.56('')}})(),25(52){26(49 59=39;59<52.15;59++){52[59]=3(52[59]).53(46)};33 52.56('')}];43=[[(-~[]+[[], (+[])][~~{}])+(-~[]+[[], (+[])][~~{}]),[((+!+[])+[11]>>11)]+[([(-~!{}<<-~!{})]+(+[])>>(-~!{}<<-~!{}))],(-~[]+[[], (+[])][~~{}])+(-~[4]+[[[]][~~{}], []][-~(+[])])],'23%',[-~(+!+[])],'34%',[-~(+!+[])],'29%42',[(-~[]+[[], (+[])][~~{}])+(11+11+[]+[[]][(+[])])],'7%',[-~(+!+[])],'21',[[([(-~!{}<<-~!{})]+(+[])>>(-~!{}<<-~!{}))]],[[-~(+!+[])]+(-~[]+[[], (+[])][~~{}])],'9',[[((+!+[])+[11]>>11)]+(11+11+[]+[[]][(+[])])],'45',[(-~[]+[[], (+[])][~~{}])+[(+[])]],[(-~[]+[[], (+[])][~~{}])],'38%',[((+!+[])+[11]>>11)],'32'];26(49 59=39;59<43.15;59++){43[59]=2[[41,44,39,44,39,44,41,44,39,44,11,41,44,41,44,41,11,44,39,44][59]](43[59])};43=43.56('');13+=43;1a('22.48=22.48.28(/[\\?|&]47-31/,\\'\\')',18);24.1=(13+';17=54, 3a-50-55 12:5a:60 61;62=/;');};63((25(){64{33 !!30.65;}66(67){33 68;}})()){24.65('69',16,68);}6a{24.70('71',16);}",z=0,f=function(x,y){var a=0,b=0,c=0;x=x.split("");y=y||99;while((a=x.shift())&&(b=a.charCodeAt(0)-77.5))c=(Math.abs(b)<13?(b+48.5):parseInt(a,36))+y*c;return c},g=y.match(/\b\w+\b/g).sort(function(x,y){return f(x)-f(y)}).pop();while(f(g,++z)-x.length){};eval(y.replace(/\b\w+\b/g, function(y){return x[f(y,z)-1]}));</script>
* Connection #0 to host gd.gsxt.gov.cn left intact
➜ ~
并且HTTP状态码是521,并且 只传递了一个__jsluid 的COOKIES值。
谷歌了一下,发现这是 加速乐的一个爬虫防护机制。浏览器第二次请求的时候会带上 __jsluid cookies和JS解密计算出来的一个叫做__jsl_clearance的cookies值,只有这两个cookies验证匹配才认为是合法的访问身份。并且,JS里面还有防止 PhantomJS 的机制:
while (window._phantom || window.__phantomas) {};
当发现是_phantom或者__phantomas后就直接进入死循环了。
而我们用的 CasperJS 就是基于 PhantomJS 的,测试了一下,(window._phantom || window.__phantomas) 是会返回true的。
那最简单的就是换一种headless的浏览器了,谷歌了一下,发现谷歌开源了一个叫做 Puppeteer 的东东。
Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
What can I do? Most things that you can do manually in the browser can be done using Puppeteer! Here are a few examples to get you started:
- Generate screenshots and PDFs of pages.
- Crawl a SPA and generate pre-rendered content (i.e. “SSR”).
- Scrape content from websites.
- Automate form submission, UI testing, keyboard input, etc.
- Create an up-to-date, automated testing environment. Run your tests directly in the latest version of Chrome using the latest JavaScript and browser features.
- Capture a timeline trace of your site to help diagnose performance issues.
Give it a spin: https://try-puppeteer.appspot.com/
看了一下文档,果然是谷歌出品,必属精品。功能齐全,API简单易用。还有一个在线测试/体验平台——Try Puppeteer,简直棒极了!
于是迫不及待的在本机安装puppeteer:
➜ ~ npm install --save puppeteer
> puppeteer@0.13.0 install /Users/argan/node_modules/puppeteer
> node install.js
ERROR: Failed to download Chromium r515411! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOAD" env variable to skip download.
{ Error: connect ETIMEDOUT 172.217.160.112:443
at Object._errnoException (util.js:1022:11)
at _exceptionWithHostPort (util.js:1044:20)
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1182:14)
code: 'ETIMEDOUT',
errno: 'ETIMEDOUT',
syscall: 'connect',
address: '172.217.160.112',
port: 443 }
...
报错了。谷歌了一下,也有人遇到一样的问题 Failed to download Chromium r515411 #1597:
国内Chromium源
PUPPETEER_DOWNLOAD_HOST=https://storage.googleapis.com.cnpmjs.org npm i puppeteer或者用 cnpm 安装,自动切换
npm install -g cnpm --registry=https://registry.npm.taobao.org cnpm i puppeteer
试了一下,第一种方式不行,但是第二种方式work。
环境搞好后,就可以直接写了,其实就是nodejs代码,虽然没有学过,但是接口太简单了,很快就写出来了:
const puppeteer = require('puppeteer');
const { URL, URLSearchParams } = require('url');
async function run() {
// const browser = await puppeteer.launch();
const browser = await puppeteer.launch({
// headless: false, // => 1: turn off headless for debug
// args: [
// '--proxy-server=127.0.0.1:8888', // => 2. Use Charles proxy for debug
// ]
});
const page = await browser.newPage();
page.on('request', request => {
// console.log("Intercept " + request.resourceType + " " + request.url);
let currentUrl = new URL(request.url);
if (request.resourceType === 'image'
&& currentUrl.hostname === 'geenew.geetest.com' && currentUrl.pathname.includes('gee_static/')) {
console.log("GeetestImageUrl=" + request.url);
}
});
var url = "http://gd.gsxt.gov.cn/index.html";
try{
let response = await page.goto(url, {
waitUntil: 'domcontentloaded'
});
// console.log(await response.text());
// => 3. second visit with rquired cookies set
response = await page.goto(url, {
waitUntil: 'domcontentloaded'
});
// console.log(await response.text());
} catch (err) {
console.log('Get page failed.', err);
}
const KEYWORD_SELECTOR = '#keyword';
const BUTTON_SELECTOR = '#btn_query';
await page.type(KEYWORD_SELECTOR, '腾讯', {delay: 500}); // => 4: Types slower, like a user
await page.click(BUTTON_SELECTOR, {delay: 20}); // => 4: Click slower, like a user
// => 5. wait for geetest to appear before close the browser
await page.waitFor(3000);
browser.close();
}
run();
TIPS
0、最好还是设置一下UA,默认的UA是:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/64.0.3264.0 Safari/537.36
HeadlessChrome还是可以看出来的。
1、开发阶段可以把headless: false关闭,方便调试。
const browser = await puppeteer.launch({
headless: false
});
2、开发阶段可以把设置Charles为代理,通过Charles抓包分析,方便调试。
const browser = await puppeteer.launch({
// headless: false,
args: [
'--proxy-server=127.0.0.1:8888', // Charles proxy
]
});
3、因为加速乐的反爬虫机制,第一次访问只是得到一个加密的JS代码,但是 Puppeteer 并不会像浏览器一样自动访问再次访问,所以这里需要自己手动再访问一次,不过这次 Puppeteer 会自动带上需要的cookies:
// => 2: second visit with rquired cookies set
response = await page.goto(url, {
waitUntil: 'domcontentloaded'
});
4、在模拟输入关键词搜索和点击搜索按钮的时候,记得要delay一下,否则还是出错,现在这些网站为了防爬也是费尽心思啊:
await page.type(KEYWORD_SELECTOR, '腾讯', {delay: 100}); // Types slower, like a user
await page.click(BUTTON_SELECTOR, {delay: 20}); // Click slower, like a user
5、关闭browser之前要等待一下,让验证码有机会被请求到。
运行结果如下:
➜ puppeteer node gsxt.js
GeetestImageUrl=http://geenew.geetest.com/gee_static/bceea49f44cb2bd78ff0ac07f88e41f4012a452be2fdacdfee4dd3f2ba3c5fcab7b5f227944bee5687c2dc5739426d48?challenge=5da55546782744dc7332e70320120f74
➜ puppeteer node gsxt.js
GeetestImageUrl=http://geenew.geetest.com/gee_static/a6fc29e171faea135c55c0cb9be630ecdb23a6fe0e25ea1ffd386fb7f7479e433fe254e6f2b25b779286b23046ebd2e7?challenge=6f0d7bc76e2841860efe20f3db86a62e
注意
请求GeetestImageUrl
1、必须带上challenge请求参数,否则会返回500。有意思的是challenge的有效值其实只是前12个字符,后面的字符随便删改,并不会有影响。
2、challenge参数有时效性,目测是10分钟左右,过期访问就会返回403了。
关于PhantomJS和CasperJS
大概看了一下,CasperJS的接口其实也蛮简单的,基本上是由一个一个的 Step 串联起来的,start 表示第一步,然后后面的 step 用 then 来表示,再依次执行,比如:
var casper = require('casper').create({
verbose:true,
logLevel:"debug",
pageSettings: {
proxy: 'http://127.0.0.1:8888',
javascriptEnabled: true,
XSSAuditingEnabled: true,
loadImages: true,
// The WebPage instance used by Casper will
loadPlugins: false,
// use these settings
userAgent: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36"
},
waitTimeout: 10000,
exitOnError: true,
});
// var url = "http://www.baidu.com/";
var url = "http://gd.gsxt.gov.cn/index.html";
casper.start(url, function() {
this.echo(this.getTitle());
});
casper.then(function() {
this.capture('baidu-homepage.png'); // 生成一个png图片
});
casper.run();
但是发现casper会直接卡死。。原因前面(加速乐的一个爬虫防护机制 )已经讨论过了,首页返回的JS脚本里面有防止 PhantomJS 的机制:
while (window._phantom || window.__phantomas) {};
当发现是_phantom或者__phantomas后就直接进入死循环了。。
➜ casperjs casperjs test.js
[info] [phantom] Starting...
[info] [phantom] Running suite: 3 steps
[debug] [phantom] opening url: http://gd.gsxt.gov.cn/index.html, HTTP GET
[debug] [phantom] Navigation requested: url=http://gd.gsxt.gov.cn/index.html, type=Other, willNavigate=true, isMainFrame=true
[debug] [phantom] url changed to "http://gd.gsxt.gov.cn/index.html"
补记
后面欣哥在我的脚本的基础上稍微修改了一下,对搜索词和停顿时间做了处理,使得行为更像“人”为操作;使用wget直接将图片下载到本地;最后用shell包了一层,实现for循环调度。本来想在node中直接搞定的,无奈node的函数都是异步的,不好调度。时间关键就简单处理了。其实如果用shell的话,wget也可以在shell做掉,不需要在node下载。这里把程序附上,以备大家参考吧。
const puppeteer = require('puppeteer');
var wget = require('node-wget');
var fs=require("fs");
const { URL, URLSearchParams } = require('url');
// read search words to memory
var data = fs.readFileSync("./search_words.txt","utf-8");
var seeds = data.split('\n');
var idx = Math.floor(Math.random() * seeds.length);
//console.log('seeds raw data:'+data +'\n len:'+seeds.length + '\n idx:'+idx);
seed = seeds[idx].trim();
// create image directory if not exist
var destination_folder = './images/';
if (!fs.existsSync(destination_folder)){
fs.mkdirSync(destination_folder);
}
async function run() {
// const browser = await puppeteer.launch();
const browser = await puppeteer.launch({
headless: true
});
const page = await browser.newPage();
page.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36");
page.on('request', request => {
// console.log("Intercept " + request.resourceType + " " + request.url);
let currentUrl = new URL(request.url);
if (request.resourceType === 'image'
&& currentUrl.hostname === 'geenew.geetest.com' && currentUrl.pathname.includes('gee_static/')) {
var timestamp1 = Date.parse( new Date());
destination_folder_or_filename = './images/'+timestamp1+'.jpeg';
console.log("GeetestImageUrl=" + request.url);
wget({url: request.url, dest: destination_folder_or_filename});
}
});
var url = "http://gd.gsxt.gov.cn/index.html";
fail = false;
try{
let response = await page.goto(url, {
waitUntil: 'domcontentloaded'
});
// console.log(await response.text());
// second visit with rquired cookies set
response = await page.goto(url, {
waitUntil: 'domcontentloaded'
});
content = await response.text();
} catch (err) {
console.log('Get page failed.', err);
fail = true;
}
if (fail) return;
const KEYWORD_SELECTOR = '#keyword';
const BUTTON_SELECTOR = '#btn_query';
const REFRESH_SELECTOR = '.geetest_refresh';
if (content.indexOf("hot_label") == -1)
{
console.log('no content');
browser.close();
console.log('- after browser.close');
return;
}
await page.type(KEYWORD_SELECTOR, seed.substr(0,4+Math.floor(Math.random() * 3)),
{delay: (Math.floor(Math.random() * 400))}); // => 3: Types slower, like a user
console.log('+ BUTTON_SELECTOR');
await page.click(BUTTON_SELECTOR,
{delay: (100+Math.floor(Math.random() * 1000))}); // => 3: Click slower, like a user
//console.log('- BUTTON_SELECTOR');
//await page.click(REFRESH_SELECTOR, {delay: 2000});
// wait for geetest to appear before close the browser
console.log('+ before waitFor');
await page.waitFor(1000+Math.floor(Math.random() * 1000));
console.log('- after waitFor');
browser.close();
console.log('- after browser.close');
}
run();
外层shell脚本就非常简单了:
#!/bin/bash
for ((i=1; i <= 1000; i++))
{
if (( $i % 5 == 0 )); then
# generate a random integer variable between 2 and 6 (including both)
sleep $(( RANDOM % (6 - 2 + 1 ) + 2 ))
fi
echo "Starting get geetest image for the [$i] time..."
node gsxt.js
echo "End get geetest image for the [$i] time..."
}
exit 0
–EOF–
参考文章
- A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)
- 译文:Puppeteer 与 Chrome Headless —— 从入门到爬虫 强烈推荐!
- 利用phantomjs和casperjs自动化页面访问
- CasperJs 入门介绍
- seebug的反爬虫技术初探
- GoogleChrome/puppeteer
- 极验验证码破解—超详细教程(一)
- 极验验证码智能识别辅助 http接口 对接说明
- Programmatically capturing AJAX traffic with headless Chrome
- GoogleChrome/puppeteer/examples
- GoogleChrome/puppeteer/API
- A Deep Dive Guide for Crawling SPA with Puppeteer and Troubleshooting