RDD核心抽象和概览

1. 什么是 RDD
The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements partitioned across the nodes of the cluster that can be operated on in parallel.
2. 怎样创建 RDD
RDD 可以通过如下方式创建:
- parallelizing an existing collection in your driver program.
- external storage system like HDFS, HBase, or any data source offering a Hadoop InputFormat.
1. parallelized collections
Parallelized collections are created by calling SparkContext’sparallelize method on an existing collection in your driver program (a Scala Seq).
// Methods for creating RDDs
/** Distribute a local Scala collection to form an RDD.
*
* @note Parallelize acts lazily. If `seq` is a mutable collection and is altered after the call
* to parallelize and before the first action on the RDD, the resultant RDD will reflect the
* modified collection. Pass a copy of the argument to avoid this.
* @note avoid using `parallelize(Seq())` to create an empty `RDD`. Consider `emptyRDD` for an
* RDD with no partitions, or `parallelize(Seq[T]())` for an RDD of `T` with empty partitions.
*/
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
/** Default level of parallelism to use when not given by user (e.g. parallelize and makeRDD). */
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
其中 defaultParallelism 是一个配置项:
spark.default.parallelism
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user.
For distributed shuffle operations like reduceByKey and join, the largest number of partitions in a parent RDD. For operations likeparallelize with no parent RDDs, it depends on the cluster manager:
- Local mode: number of cores on the local machine
- Mesos fine grained mode: 8
- Others: total number of cores on all executor nodes or 2, whichever is larger
这个配置项是一个比较重要的配置项,基本上都需要根据任务执行情况进行适当配置。例如如果发现大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大,那么可以适当的调大 spark.default.parallelism;反之,如果发现spark计算出来的partition非常巨大,远远超过申请的cores数量,导致每个task完成时间都是几毫秒或者零点几毫秒(一个 partition 对应一个 task),执行起来非常缓慢,那么适当的调低spark.default.parallelism可以起到提到执行效率的作用。
例子
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
// 设置分区数为10个
val distData = sc.parallelize(data, 10)
2. External Datasets
Spark can create distributed datasets from any storage source supported by Hadoop, including your local file system, HDFS, Cassandra, HBase, Amazon S3, etc. Spark支持文本文件,二进制文件 SequenceFiles,以及任何其他的 Hadoop InputFormat.
NOTES
1、All of Spark’s file-based input methods, including textFile, support running on directories, compressed files, and wildcards as well. For example, you can use textFile(“/my/directory”), textFile(“/my/directory/.txt”), and textFile(“/my/directory/.gz”).
2、The textFile method also takes an optional second argument for controlling the number of partitions of the file. By default, Spark creates one partition for each block of the file (blocks being 128MB by default in HDFS), but you can also ask for a higher number of partitions by passing a larger value. Note that you cannot have fewer partitions than blocks.
3、对于二进制文件,需要使用 SparkContext 的 sequenceFile[K, V] 方法,其中 K 和 V 分别是二进制文件中 key 和 value 的类型。它们必须是 Hadoop 的 Writable 接口的实现类,例如 IntWritable 和 Text。对于常见的基本类型,Spark提供了对应的Writables实现,例如,你可以直接使用 sequenceFile[Int, String]来读取 IntWritable 类型的 Key 和 Text 类型的 Value。
4、对于其他的 Hadoop InputFormats,你可以使用 SparkContext.hadoopRDD 方法 :
/**
* Get an RDD for a Hadoop-readable dataset from a Hadoop JobConf given its InputFormat and other
* necessary info (e.g. file name for a filesystem-based dataset, table name for HyperTable),
* using the older MapReduce API (`org.apache.hadoop.mapred`).
*
* @param conf JobConf for setting up the dataset. Note: This will be put into a Broadcast.
* Therefore if you plan to reuse this conf to create multiple RDDs, you need to make
* sure you won't modify the conf. A safe approach is always creating a new conf for
* a new RDD.
* @param inputFormatClass Class of the InputFormat
* @param keyClass Class of the keys
* @param valueClass Class of the values
* @param minPartitions Minimum number of Hadoop Splits to generate.
*
* @note Because Hadoop's RecordReader class re-uses the same Writable object for each
* record, directly caching the returned RDD or directly passing it to an aggregation or shuffle
* operation will create many references to the same object.
* If you plan to directly cache, sort, or aggregate Hadoop writable objects, you should first
* copy them using a `map` function.
*/
def hadoopRDD[K, V](
conf: JobConf,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)]
对于基于新的MapReduce API的 InputFormats,你可以使用 SparkContext.newAPIHadoopRDD 方法。
/**
* Get an RDD for a given Hadoop file with an arbitrary new API InputFormat
* and extra configuration options to pass to the input format.
*
* @param conf Configuration for setting up the dataset. Note: This will be put into a Broadcast.
* Therefore if you plan to reuse this conf to create multiple RDDs, you need to make
* sure you won't modify the conf. A safe approach is always creating a new conf for
* a new RDD.
* @param fClass Class of the InputFormat
* @param kClass Class of the keys
* @param vClass Class of the values
*
* @note Because Hadoop's RecordReader class re-uses the same Writable object for each
* record, directly caching the returned RDD or directly passing it to an aggregation or shuffle
* operation will create many references to the same object.
* If you plan to directly cache, sort, or aggregate Hadoop writable objects, you should first
* copy them using a `map` function.
*/
def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V]): RDD[(K, V)]
5、RDD.saveAsObjectFile 和 SparkContext.objectFile support saving an RDD in a simple format consisting of serialized Java objects. While this is not as efficient as specialized formats like Avro, it offers an easy way to save any RDD.
3. RDD 的操作
Spark RDD 支持两种类型的操作:
- Transformations : create a new dataset from an existing one
- Actions : Return a value to the driver program after running a computation on the dataset.
NOTES
All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently. For example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist (or cache) method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
1. Transformations
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T. |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T. |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process’s stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
NOTES
Spark 对 RDD Transformation 是惰性计算的,只有在 Action 操作时,才会真正计算。
2. Actions
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop’s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (java and Scala) | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
3. Shuffle operations
上述某些操作(算子)会导致 Spark 触发一个shuffle操作,The shuffle is Spark’s mechanism for re-distributing data so that it’s grouped differently across partitions. This typically involves copying data across executors and machines, making the shuffle a complex and costly operation.
shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算子,都会触发shuffle操作。
例如,reduceByKey 算子,需要对所有相同的 key 做 reduce 操作,但是并不是所有相同的 key 都落在一个 partition,甚至同一台机器上;另一方面,一个 spark task 只能够操作一个 partition,这就需要先将数据按照 key 进行重新发布,这个过程就叫做 shuffle。
In Spark, data is generally not distributed across partitions to be in the necessary place for a specific operation. During computations, a single task will operate on a single partition - thus, to organize all the data for a single reduceByKey reduce task to execute, Spark needs to perform an all-to-all operation. It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle.
哪些操作会引起 shuffle :
- 重分区(repartition)操作算子,比如 repartition 和 coalesce
- 聚合(ByKey)操作算子 (除了 counting),比如 groupByKey 和 reduceByKey。
- 连接(join)操作算子,比如 cogroup 和 join。
/** 去重 **/
def distinct()
def distinct(numPartitions: Int)
/** 聚合 **/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
/** 排序 **/
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
/** 重分区 **/
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)
/** 集合或者表操作 **/
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
TIPS shuffle 和 数据倾斜
shuffle 过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原因。
而且另一方面,shuffle 会引起数据倾斜,导致计算短板。具体可以参见笔者的另一篇文章: Spark数据倾斜及其解决方案。
4. RDD 的持久化
Spark中对于一个RDD执行多次算子的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
因此对于这种情况,Spark 提供了一种机制,可以对多次使用的RDD进行持久化。此时Spark就会根据你的持久化策略,将RDD中的数据保存到内存或者磁盘中。以后每次对这个RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,然后执行算子,而不会从源头处重新计算一遍这个RDD,再执行算子操作。
对多次使用的RDD进行持久化的代码示例:
// 如果要对一个RDD进行持久化,只要对这个RDD调用cache()和persist()即可。
// 正确的做法。
// cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中。
// 此时再对rdd1执行两次算子操作时,只有在第一次执行map算子时,才会将这个rdd1从源头处计算一次。
// 第二次执行reduce算子时,就会直接从内存中提取数据进行计算,不会重复计算一个rdd。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").cache()
rdd1.map(...)
rdd1.reduce(...)
// persist()方法表示:手动选择持久化级别,并使用指定的方式进行持久化。
// 比如说,StorageLevel.MEMORY_AND_DISK_SER表示,内存充足时优先持久化到内存中,内存不充足时持久化到磁盘文件中。
// 而且其中的_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
// 序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,从而发生频繁GC。
val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").persist(StorageLevel.MEMORY_AND_DISK_SER)
rdd1.map(...)
rdd1.reduce(...)
对于persist()方法而言,我们可以根据不同的业务场景选择不同的持久化级别:
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
| OFF_HEAP (experimental) | 跟 MEMORY_ONLY_SER 类似,但是将数据保存在 off-head memory,这个要求开启 off-heap memory。 |
5. applications, jobs, stages 和 tasks
Applications
一个 spark Application 由一个或多个 job 组成。
Jobs
一个 job 是由一个或多个 stage 组成的(取决于是否需要 Shuffle)。对 RDD 每次执行一个 action 操作,都会触发提交一个 job(即一个 job 对应一个 action 算子,job 的数量取决于 action 的个数)。
Stages
一个 stage 由一个或多个 task 组成。RDD 经过一系列的转换会生成一个 DAG,spark 会根据宽依赖(wide dependency)将 DAG 划分为不同的 stage。
Tasks
一个 task 负责处理 RDD 一个 partition 的数据。每个 stage 里面的 task 的数量是由该 stage 中最后一个 RDD 的 partition 的数量所决定的。
窄依赖和宽依赖 & Stage 的划分
窄依赖和宽依赖
Spark中RDD的高效与DAG(有向无环图)有很大的关系,在DAG调度中需要对计算的过程划分Stage,划分的依据就是RDD之间的依赖关系。RDD之间的依赖关系分为两种,宽依赖(wide dependency/shuffle dependency)和窄依赖(narrow dependency)。
1、窄依赖 : 父 RDD 的每个分区都只被子 RDD 的一个分区使用;反之,一个子 RDD 的数据可以来源于多个父 RDD。例如 map、filter、union 等操作会产生窄依赖。
即窄依赖又分为两种:
- 一对一的依赖,即 OneToOneDependency
- 范围的依赖,即 RangeDependency,它仅仅被
org.apache.spark.rdd.UnionRDD使用。UnionRDD 是把多个 RDD 合成一个 RDD,这些 RDD 是被拼接而成,即每个 parent RDD 的 Partition 的相对顺序不会变,只不过每个 parent RDD在 UnionRDD 中的 Partition 的起始位置不同
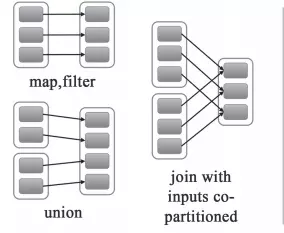
2、宽依赖 : 父 RDD 的分区被子 RDD 的多个分区使用,例如 groupByKey、reduceByKey、sortByKey 等操作会产生宽依赖,这时候会产生 shuffle。
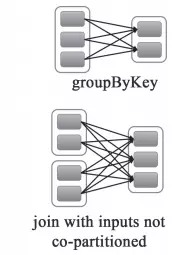
TIPS: 窄依赖与窄依赖比较
1、宽依赖往往对应着 shuffle 操作,需要在运行的过程中将同一个 RDD 分区传入到不同的 RDD 分区中,中间可能涉及到多个节点之间数据的传输,而窄依赖的每个父 RDD 分区通常只会传入到另一个子 RDD 分区,通常在一个节点内完成。
2、当 RDD 分区丢失时,对于窄依赖来说,由于父 RDD 的一个分区只对应一个子 RDD 分区,这样只需要重新计算与子 RDD 分区对应的父 RDD 分区就行。这个计算对数据的利用是 100% 的
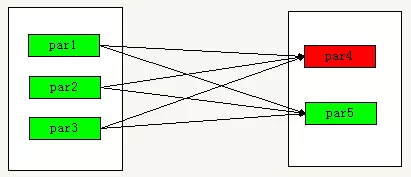
3、当 RDD 分区丢失时,对于宽依赖来说,重算的父 RDD 分区只有一部分数据是对应丢失的子 RDD 分区的,另一部分就造成了多余的计算。宽依赖中的子 RDD 分区通常来自多个父 RDD 分区,极端情况下,所有父 RDD 都有可能重新计算。如下图,par4 丢失,则需要重新计算 par1,par2,par3,产生了冗余数据 par5:
Stage 的划分
Spark 任务会根据 RDD 之间的依赖关系,形成一个 DAG 有向无环图,DAG 会提交给 DAGScheduler,DAGScheduler 会把 DAG 划分相互依赖的多个 stage,划分 stage 的依据就是 RDD 之间的宽窄依赖。遇到宽依赖就划分 stage,每个 stage 包含一个或多个 task 任务。然后将这些 task 以 taskSet 的形式提交给 TaskScheduler 运行。stage是由一组并行的task组成。
Stage 的划分,简单的说是以 shuffle 和 result 这两种类型来划分。在 Spark 中有两类 task,一类是 shuffleMapTask,一类是 resultTask,第一类 task 的输出是 shuffle 所需数据,第二类 task 的输出是 result,stage 的划分也以此为依据,shuffle 之前的所有变换是一个 stage,shuffle 之后的操作是另一个 stage。
例如 rdd.parallize(1 to 10).foreach(println) 这个操作没有 shuffle,直接就输出了,那么只有它的 task 是 resultTask,stage 也只有一个。
但是对于 rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println) 这个语句,这个 job 因为有 reduce,所以有一个 shuffle 过程,那么 reduceByKey 之前的是一个 stage,执行 shuffleMapTask,输出 shuffle 所需的数据,reduceByKey 到最后是一个 stage,直接就输出结果了。如果 job 中有多次 shuffle,那么每个 shuffle 前后各是一个 stage。