方法一:直接在界面上查看
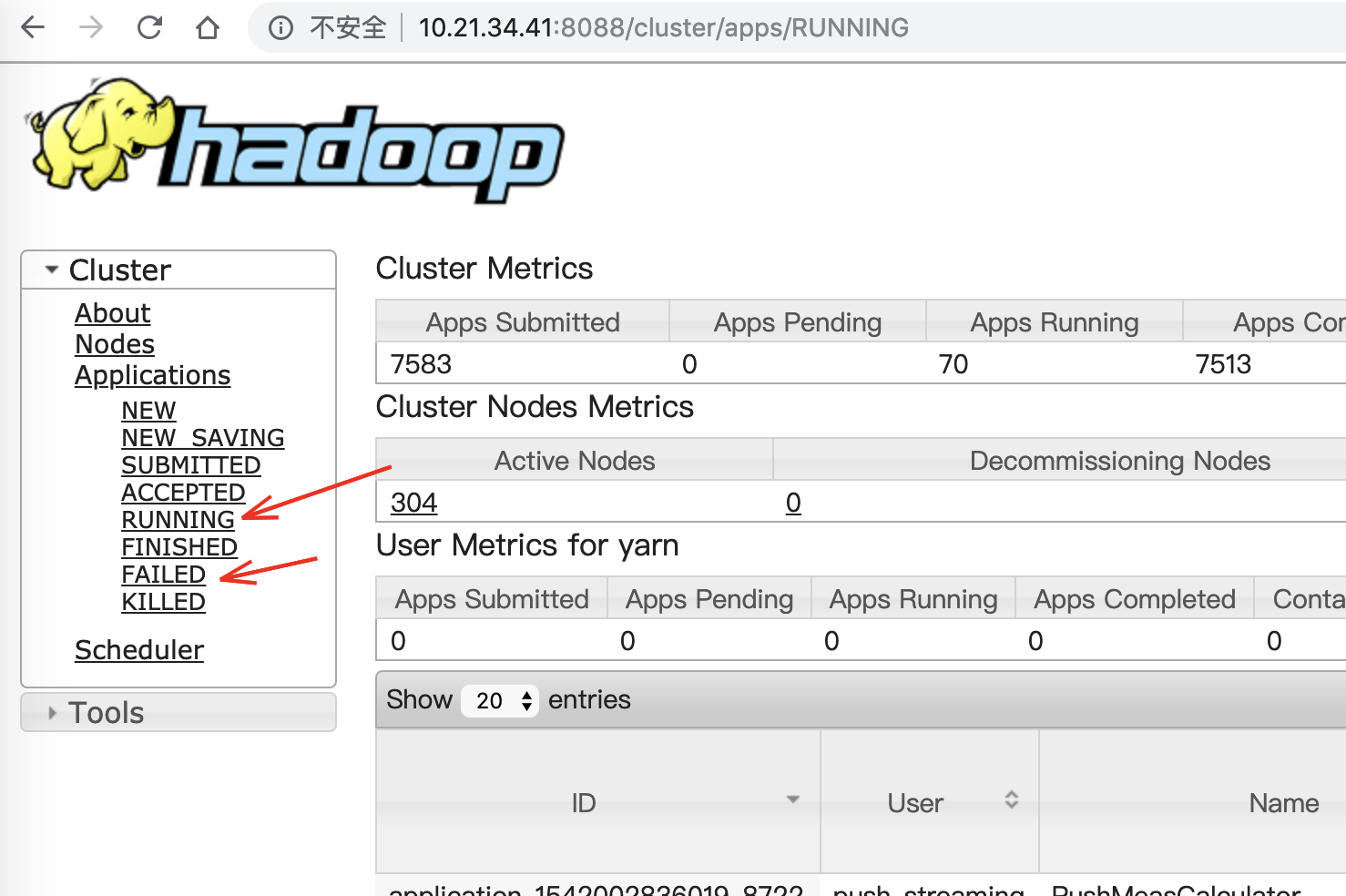
如果你运行在 YARN 模式,你可以在 ResourceManager 节点的 WEB UI 页面根据 任务状态、用户名 或者 applicationId Search 到你的应用。然后
- 点击表格中
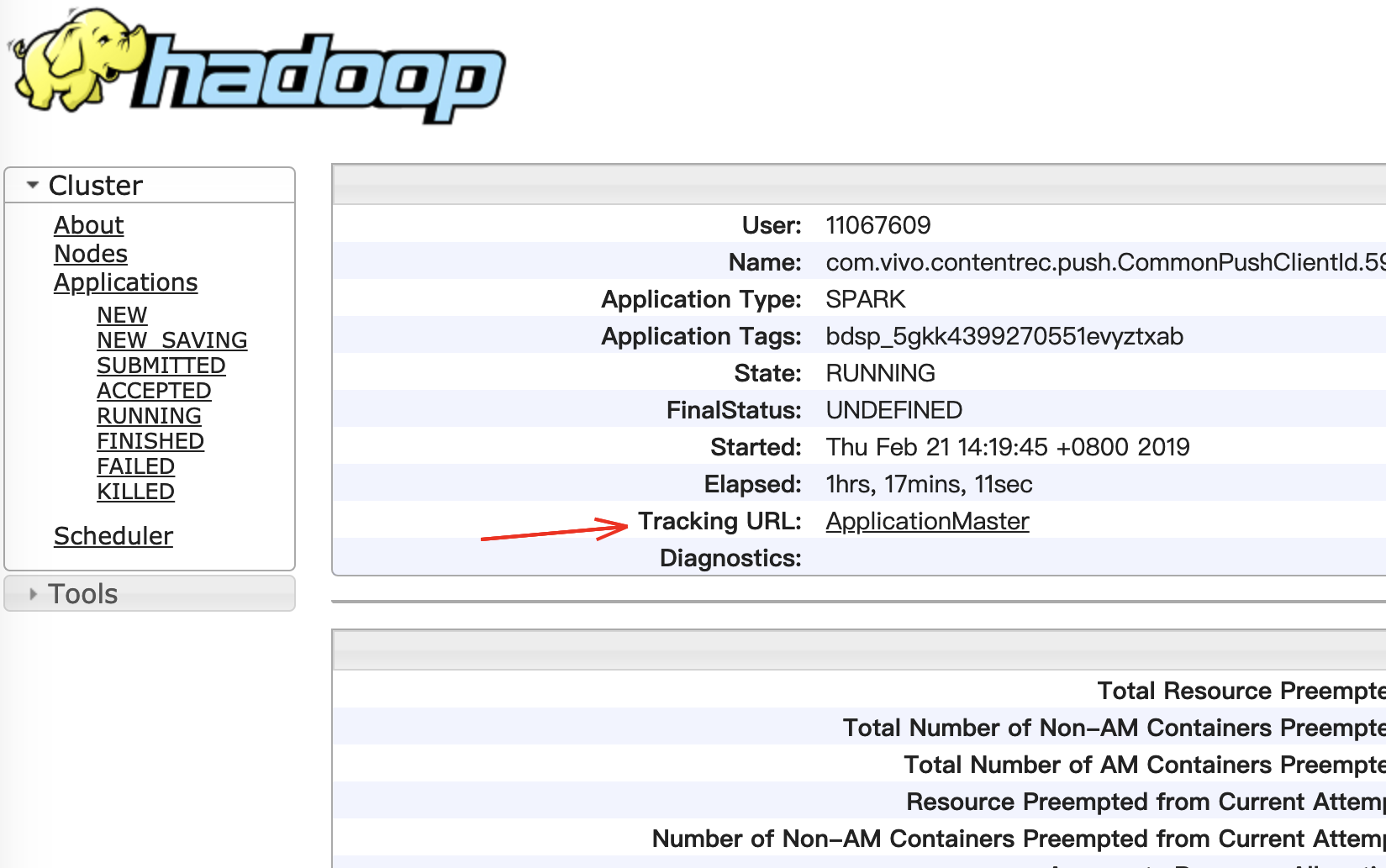
Tracking UI列的History 链接;或者 - 点击相关的 ApplicationId 链接,进入到详情页面点击上面的
Tracking URL: History链接
就进入到Spark作业监控的 WEB UI 界面,这个页面就是你 Spark 应用程序历史执行界面:例如http://bj01-prd-hadoop001.arganzheng.lan:18088/history/application_1537448956025_2516133/jobs/。到这个界面之后,可以点击 Executors 菜单,这时候你可以进入到 Spark 程序的 Executors 界面,里面列出所有Executor信息,以表格的形式展示,在表格中有 Logs 这列,里面就是你Spark应用程序运行的日志。
也可以从 driver 日志中直接拿到程序的 web UI 地址(Tracking URL),直接在driver日志中搜索“tracking URL“并将该URL在浏览器中打开:
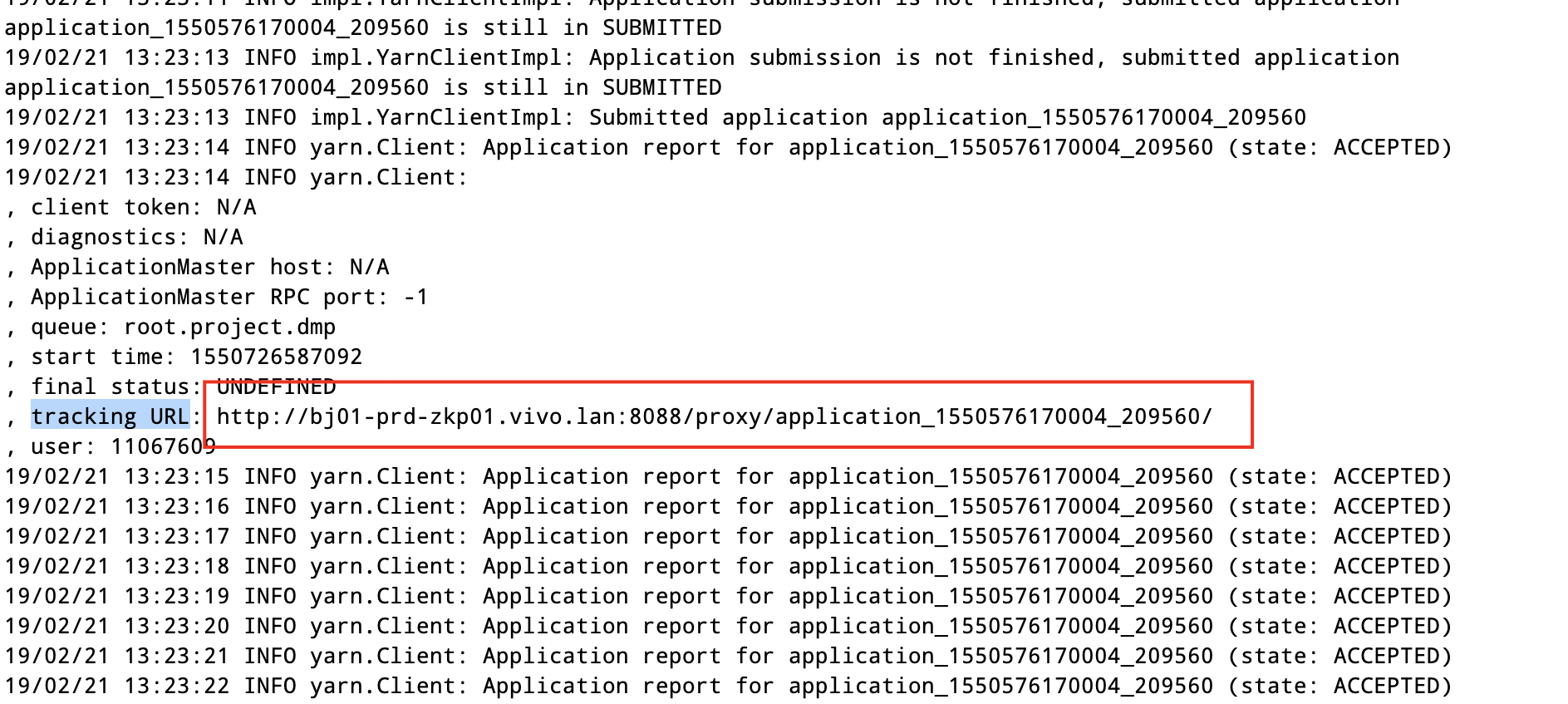
方法二: 直接查看 HDFS 上的日志文件
例如用 xfhuang 账户运行的日志,可以用下面命令这里看到所有 application 的日志:
$ hadoop fs -ls /tmp/logs/xfhuang/logs/
Found 33 items
drwxrwx---+ - xfhuang hadoop 0 2018-10-18 17:06 /tmp/logs/xfhuang/logs/application_1537448956025_2344152
drwxrwx---+ - xfhuang hadoop 0 2018-10-18 17:42 /tmp/logs/xfhuang/logs/application_1537448956025_2346489
...
drwxrwx---+ - xfhuang hadoop 0 2018-10-19 21:16 /tmp/logs/xfhuang/logs/application_1537448956025_2448690
drwxrwx---+ - xfhuang hadoop 0 2018-10-20 15:47 /tmp/logs/xfhuang/logs/application_1537448956025_2514112
drwxrwx---+ - xfhuang hadoop 0 2018-10-20 16:39 /tmp/logs/xfhuang/logs/application_1537448956025_2516133
如果要看具体的某个 applicationId 产生的日志,则直接指定:
$ hadoop fs -ls /tmp/logs/xfhuang/logs/application_1537448956025_2409589
Found 237 items
-rw-r-----+ 1 xfhuang hadoop 11301 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bigdata-offline-hadoop0100.bjthq.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 205262 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bigdata-offline-hadoop0116.bjthq.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 11301 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bigdata-offline-hadoop0118.bjthq.arganzheng.lan_8041
...
-rw-r-----+ 1 xfhuang hadoop 11301 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bigdata-offline-hadoop0485.bjthq.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 623665 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bigdata-offline-hadoop0491.bjthq.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 11287 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bj01-prd-hadoop008.arganzheng.lan_8041
...
-rw-r-----+ 1 xfhuang hadoop 22240 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-dm-dn0482.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 394399 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-dm-dn0483.arganzheng.lan_8041
...
-rw-r-----+ 1 xfhuang hadoop 229187 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bp-bigdata-offline-hadoop0616.bj01.arganzheng.lan_8041
是分机器存放的,可以具体看某一台机器的日志:
$ hadoop fs -ls /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-bi-dn0008.arganzheng.lan_8041
-rw-r-----+ 1 xfhuang hadoop 154095 2018-10-19 10:11 /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-bi-dn0008.arganzheng.lan_8041
$ hadoop fs -cat /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-bi-dn0008.arganzheng.lan_8041 | head
��h��9�A@���P VERSIONAPPLICATION_ACLVIEW_APPnobody,xfhuang
MODIFY_APPnobody,xfhuangAPPLICATION_OWNER xfhuang/-container_e93_1537448956025_2409589_01_000527�Xxcontainer-localizer-syslog1682018-10-19 09:49:41,402 WARN [main] org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer: Localization running as nobody not xfhuang
stderr15347718/10/19 09:49:43 INFO executor.CoarseGrainedExecutorBackend: Started daemon with process name: 7201@bjthq-bi-dn0008.arganzheng.lan
18/10/19 09:49:43 INFO executor.CoarseGrainedExecutorBackend: Registered signal handlers for [TERM, HUP, INT]
18/10/19 09:49:44 INFO spark.SecurityManager: Changing view acls to: nobody,xfhuang
18/10/19 09:49:44 INFO spark.SecurityManager: Changing modify acls to: nobody,xfhuang
18/10/19 09:49:44 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(nobody, xfhuang); users with modify permissions: Set(nobody, xfhuang)
18/10/19 09:49:44 INFO spark.SecurityManager: Changing view acls to: nobody,xfhuang
18/10/19 09:49:44 INFO spark.SecurityManager: Changing modify acls to: nobody,xfhuang
18/10/19 09:49:44 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(nobody, xfhuang); users with modify permissions: Set(nobody, xfhuang)
cat: Unable to write to output stream.
下载到本地方便查看:
$ hadoop fs -get /tmp/logs/xfhuang/logs/application_1537448956025_2409589/bjthq-bi-dn0008.arganzheng.lan_8041 /home/xfhuang/temp/
里面的日志就是这台机器上这个 applicationId 下 executor 的运行日志。
不过需要grep所有的文件才知道哪个日志文件是 ApplicationMaster 的。比如:grep -Fnrs “ApplicationMaster”。
方法三:通过 yarn logs -applicationId 命令查看
如果是 YARN 模式,最简单地收集日志的方式是使用 YARN 的日志收集工具(yarn logs -applicationId),这个工具可以收集你应用程序相关的运行日志,但是这个工具是有限制的:应用程序必须运行完,因为YARN必须首先聚合这些日志;而且你必须开启日志聚合功能(yarn.log-aggregation-enable,在默认情况下,这个参数是 false)。
$ yarn logs -applicationId application_1537448956025_2409589 | head
18/10/20 17:14:06 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm130
Unable to get ApplicationState. Attempting to fetch logs directly from the filesystem.
Container: container_e93_1537448956025_2409589_01_000232 on bigdata-offline-hadoop0100.bjthq.arganzheng.lan_8041
============================================================================================================
LogType:container-localizer-syslog
Log Upload Time:Fri Oct 19 10:11:06 +0800 2018
LogLength:168
Log Contents:
2018-10-19 09:46:41,580 WARN [main] org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer: Localization running as nobody not xfhuang
说明
1、Spark 程序的日志分为 driver 日志和 executor 日志,在 yarn-client 模式下,driver 日志即是 spark-submit(或 spark2-submit)运行时的打印日志,这个日志是我们排查问题首先要拿到的。在 yarn-cluster 模式下 driver 日志在某个 container 上。
2、Spark 程序的日志根据 spark 程序所在的阶段需要去不同的地方查看,比如程序正在运行时可以通过程序本身的 web UI 查看运行时的日志,程序结束后,web UI 就退出了,Spark 会将日志移动到 Spark History。Spark程序结束后,就无法从 web UI 查看日志了,因为此时 driver 已经退出,而日志被移动到 spark history server,而 history server 保留日志是有时间和数量限制的;如果中 history server 中找不到,则需要从 HDFS的 /tmp/logs 目录下载 或者通过 yarn logs -applicationId 命令查看。
3、Spark Client 和 Spark Cluster的区别:
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业。
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。