背景
最近要把原来在BB做的那套集中式日志监控系统迁移到Mobojoy这边,原来的实现方案是: Log Agent => Log Server => ElasticSearch => Kibana,其中Log Agent和Log Server之间走的是Thrift RPC,自己实现了一个简单的负载均衡(WRB)。
原来的方案其实运行的挺好的,异步化Agent对应用性能基本没有影响。支持我们这个每天几千万PV的应用一点压力都没有。不够有个缺点就是如果错误日志暴增,Log Server这块处理不过来,会导致消息丢失。当然我们量级没有达到这个程度,而且也是可以通过引入队列缓冲一下处理。不过现在综合考虑,其实直接使用消息队列会更简单。PRC,负载均衡,负载缓冲都内建实现了。另一种方式是直接读取日志,类似于logstash或者flume的方式。不过考虑到灵活性还是决定使用消息队列的方式,反正我们已经部署了Zookeeper。调研了一下,Kafka是最适合做这个数据中转和缓冲的。于是,打算把方案改成: Log Agent => Kafa => ElasticSearch => Kibana。
Kafka介绍
Kafka基本概念
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
- Message
- 消息是Kafka通讯的基本单位,有一个固定长度的消息头和一个可变长度的消息体(payload)构成。在Java客户端中又称之为记录(Record)。
- 消息结构各部分说明如下:
- CRC32: CRC32校验和,4个字节。
- magic: Kafka服务程序协议版本号,用于做兼容。1个字节。
- attributes: 该字段占1字节,其中低两位用来表示压缩方式,第三位表示时间戳类型(0表示LogCreateTime,1表示LogAppendTime),高四位为预留位置,暂无实际意义。
- timestamp: 消息时间戳,当
magic > 0时消息头必须包含该字段。8个字节。 - key-length: 消息key长度,4个字节。
- key: 消息key实际数据。
- payload-length: 消息实际数据长度,4个字节。
- payload: 消息实际数据
- 在实际存储一条消息还包括12字节的额外开销(LogOverhead):
- 消息的偏移量: 8字节,类似于消息的Id。
- 消息的总长度: 4字节
- Partition:
- Partition(分区)是物理上的概念,每个Topic包含一个或多个Partition。
- 每个分区由一系列有序的不可变的消息组成,是一个有序队列。
- 每个分区在物理上对应为一个文件夹,分区的命名规则为
${topicName}-{partitionId},如__consumer_offsets-0。 - 分区目录下存储的是该分区的日志段,包括日志数据文件和两个索引文件。
- 每条消息被追加到相应的分区中,是顺序写磁盘,因此效率非常高,这也是Kafka高吞吐率的一个重要保证。
- kafka只能保证一个分区内的消息的有序性,并不能保证跨分区消息的有序性。
- LogSegment:
- 日志文件按照大小或者时间滚动切分成一个或者多个日志段(LogSegment),其中日志段大小由配置项
log.segment.bytes指定,默认是1GB。时间长度则是根据log.roll.ms或者log.roll.hours配置项设置;当前活跃的日志段称之为活跃段(activeSegment)。 - 不同于普通的日志文件,Kafka的日志段除了有一个具体的日志文件之外,还有两个辅助的索引文件:
- 数据文件
- 数据文件是以
.log为文件后缀名的消息集文件(FileMessageSet),用于保存消息实际数据 - 命名规则为:由数据文件的第一条消息偏移量,也称之为基准偏移量(
BaseOffset),左补0构成20位数字字符组成 - 每个数据文件的基准偏移量就是上一个数据文件的
LEO+1(第一个数据文件为0)
- 数据文件是以
- 偏移量索引文件
- 文件名与数据文件相同,但是以
.index为后缀名。它的目的是为了快速根据偏移量定位到消息所在的位置。 - 首先Kafka将每个日志段以
BaseOffset为key保存到一个ConcurrentSkipListMap跳跃表中,这样在查找指定偏移量的消息时,用二分查找法就能快速定位到消息所在的数据文件和索引文件 - 然后在索引文件中通过二分查找,查找值小于等于指定偏移量的最大偏移量,最后从查找出的最大偏移量处开始顺序扫描数据文件,直到在数据文件中查询到偏移量与指定偏移量相等的消息
- 需要注意的是并不是每条消息都对应有索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引,我们可以通过
index.interval.bytes设置索引跨度。
- 文件名与数据文件相同,但是以
- 时间戳索引文件
- Kafka从0.10.1.1版本开始引入了一个基于时间戳的索引文件,文件名与数据文件相同,但是以
.timeindex作为后缀。它的作用则是为了解决根据时间戳快速定位消息所在位置。 - Kafka API提供了一个
offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)方法,该方法会返回时间戳大于等于待查询时间的第一条消息对应的偏移量和时间戳。这个功能其实挺好用的,假设我们希望从某个时间段开始消费,就可以用offsetsForTimes()方法定位到离这个时间最近的第一条消息的偏移量,然后调用seek(TopicPartition, long offset)方法将消费者偏移量移动过去,然后调用poll()方法长轮询拉取消息。
- Kafka从0.10.1.1版本开始引入了一个基于时间戳的索引文件,文件名与数据文件相同,但是以
- 数据文件
- 日志文件按照大小或者时间滚动切分成一个或者多个日志段(LogSegment),其中日志段大小由配置项
- Producer:
- 负责发布消息到Kafka broker。
- 生产者的一些重要的配置项:
request.required.acks: Kafka为生产者提供了三种消息确认机制(ACK),用于配置broker接到消息后向生产者发送确认信息,以便生产者根据ACK进行相应的处理,该机制通过属性request.required.acks设置,取值可以为0, -1, 1,默认是1。- acks=0: 生产者不需要等待broker返回确认消息,而连续发送消息。
- acks=1: 生产者需要等待Leader副本已经成功将消息写入日志文件中。这种方式在一定程度上降低了数据丢失的可能性,但仍无法保证数据一定不会丢失。因为没有等待follower副本同步完成。
- acks=-1: Leader副本和所有的ISR列表中的副本都完成数据存储时才会向生产者发送确认消息。为了保证数据不丢失,需要保证同步的副本至少大于1,通过参数
min.insync.replicas设置,当同步副本数不足次配置项时,生产者会抛出异常。但是这种方式同时也影响了生产者发送消息的速度以及吞吐率。
message.send.max.retries: 生产者在放弃该消息前进行重试的次数,默认是3次。retry.backoff.ms: 每次重试之前等待的时间,单位是ms,默认是100。queue.buffering.max.ms: 在异步模式下,消息被缓存的最长时间,当到达该时间后消息被开始批量发送;若在异步模式下同时配置了缓存数据的最大值batch.num.messages,则达到这两个阈值的任何一个就会触发消息批量发送。默认是1000ms。queue.buffering.max.messages: 在异步模式下,可以被缓存到队列中的未发送的最大消息条数。默认是10000。queue.enqueue.timeout.ms:=0: 表示当队列没满时直接入队,满了则立即丢弃<0: 表示无条件阻塞且不丢弃>0: 表示阻塞达到该值时长抛出QueueFullException异常
batch.num.messages: Kafka支持批量消息(Batch)向broker的特定分区发送消息,批量大小由属性batch.num.messages设置,表示每次批量发送消息的最大消息数,当生产者采用同步模式发送时改配置项将失效。默认是200。request.timeout.ms: 在需要acks时,生产者等待broker应答的超时时间。默认是1500ms。send.buffer.bytes: Socket发送缓冲区大小。默认是100kb。topic.metadata.refresh.interval.ms: 生产者定时请求更新主题元数据的时间间隔。若设置为0,则在每个消息发送后都会去请求更新数据。默认是5min。client.id: 生产者id,主要方便业务用来追踪调用定位问题。默认是console-producer。
- Consumer & Consumer Group & Group Coordinator:
- Consumer: 消息消费者,向Kafka broker读取消息的客户端。Kafka0.9版本发布了基于Java重新写的新的消费者,它不再依赖scala运行时环境和zookeeper。
- Consumer Group: 每个消费者都属于一个特定的Consumer Group,可通过
group.id配置项指定,若不指定group name则默认为test-consumer-group。 - Group Coordinator: 对于每个Consumer group,会选择一个brokers作为消费组的协调者。
- 每个消费者也有一个全局唯一的id,可通过配置项
client.id指定,如果不指定,Kafka会自动为该消费者生成一个格式为${groupId}-${hostName}-${timestamp}-${UUID前8个字符}的全局唯一id。 - Kafka提供了两种提交consumer_offset的方式:Kafka自动提交 或者 客户端调用KafkaConsumer相应API手动提交。
- 自动提交: 并不是定时周期性提交,而是在一些特定事件发生时才检测与上一次提交的时间间隔是否超过
auto.commit.interval.ms。enable.auto.commit=trueauto.commit.interval.ms
- 手动提交
enable.auto.commit=falsecommitSync(): 同步提交commitAsync(): 异步提交
- 自动提交: 并不是定时周期性提交,而是在一些特定事件发生时才检测与上一次提交的时间间隔是否超过
- 消费者的一些重要的配置项:
- group.id: A unique string that identifies the consumer group this consumer belongs to.
- client.id: The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request.
- bootstrap.servers: A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
- key.deserializer: Deserializer class for key that implements the org.apache.kafka.common.serialization.Deserializer interface.
- value.deserializer: Deserializer class for value that implements the org.apache.kafka.common.serialization.Deserializer interface.
- fetch.min.bytes: The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request.
- fetch.max.bytes: The maximum amount of data the server should return for a fetch request.
- max.partition.fetch.bytes: The maximum amount of data per-partition the server will return.
- max.poll.records: The maximum number of records returned in a single call to poll().
- heartbeat.interval.ms: The expected time between heartbeats to the consumer coordinator when using Kafka’s group management facilities.
- session.timeout.ms: The timeout used to detect consumer failures when using Kafka’s group management facility.
- enable.auto.commit: If true the consumer’s offset will be periodically committed in the background.
- ISR: Kafka在ZK中动态维护了一个ISR(In-Sync Replica),即保持同步的副本列表,该列表中保存的是与leader副本保持消息同步的所有副本对应的brokerId。如果一个副本宕机或者落后太多,则该follower副本将从ISR列表中移除。
- Zookeeper:
- Kafka利用ZK保存相应的元数据信息,包括:broker信息,Kafka集群信息,旧版消费者信息以及消费偏移量信息,主题信息,分区状态信息,分区副本分片方案信息,动态配置信息,等等。
- Kafka在zk中注册节点说明:
- /consumers: 旧版消费者启动后会在ZK的该节点下创建一个消费者的节点
- /brokers/seqid: 辅助生成的brokerId,当用户没有配置
broker.id时,ZK会自动生成一个全局唯一的id。 - /brokers/topics: 每创建一个主题就会在该目录下创建一个与该主题同名的节点。
- /borkers/ids: 当Kafka每启动一个KafkaServer时就会在该目录下创建一个名为
{broker.id}的子节点 - /config/topics: 存储动态修改主题级别的配置信息
- /config/clients: 存储动态修改客户端级别的配置信息
- /config/changes: 动态修改配置时存储相应的信息
- /admin/delete_topics: 在对主题进行删除操作时保存待删除主题的信息
- /cluster/id: 保存集群id信息
- /controller: 保存控制器对应的brokerId信息等
- /isr_change_notification: 保存Kafka副本ISR列表发生变化时通知的相应路径
- Kafka在启动或者运行过程中会在ZK上创建相应的节点来保存元数据信息,通过监听机制在这些节点注册相应的监听器来监听节点元数据的变化。
TIPS
如果跟ES对应,Broker相当于Node,Topic相当于Index,Message相对于Document,而Partition相当于shard。LogSegment相对于ES的Segment。
如何查看消息内容(Dump Log Segments)
我们在使用kafka的过程中有时候可以需要查看我们生产的消息的各种信息,这些消息是存储在kafka的日志文件中的。由于日志文件的特殊格式,我们是无法直接查看日志文件中的信息内容。Kafka提供了一个命令,可以将二进制分段日志文件转储为字符类型的文件:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments
Parse a log file and dump its contents to the console, useful for debugging a seemingly corrupt log segment.
Option Description
------ -----------
--deep-iteration 使用深迭代而不是浅迭代
--files <file1, file2, ...> 必填。输入的日志段文件,逗号分隔
--key-decoder-class 自定义key值反序列化器。必须实现`kafka.serializer.Decoder` trait。所在jar包需要放在`kafka/libs`目录下。(默认是`kafka.serializer.StringDecoder`)。
--max-message-size <Integer: size> 消息最大的字节数(默认为5242880)
--print-data-log 同时打印出日志消息
--value-decoder-class 自定义value值反序列化器。必须实现`kafka.serializer.Decoder` trait。所在jar包需要放在`kafka/libs`目录下。(默认是`kafka.serializer.StringDecoder`)。
--verify-index-only 只是验证索引不打印索引内容
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.log --print-data-log
Dumping /tmp/kafka-logs/test-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1498104812192 isvalid: true payloadsize: 11 magic: 1 compresscodec: NONE crc: 3271928089 payload: hello world
offset: 1 position: 45 CreateTime: 1498104813269 isvalid: true payloadsize: 14 magic: 1 compresscodec: NONE crc: 242183772 payload: hello everyone
注意:这里 --print-data-log 是表示查看消息内容的,不加此项只能看到Header,看不到payload。
也可以用来查看index文件:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.index --print-data-log
Dumping /tmp/kafka-logs/test-0/00000000000000000000.index
offset: 0 position: 0
timeindex文件也是OK的:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.timeindex --print-data-log
Dumping /tmp/kafka-logs/test-0/00000000000000000000.timeindex
timestamp: 1498104813269 offset: 1
Found timestamp mismatch in :/tmp/kafka-logs/test-0/00000000000000000000.timeindex
Index timestamp: 0, log timestamp: 1498104812192
Found out of order timestamp in :/tmp/kafka-logs/test-0/00000000000000000000.timeindex
Index timestamp: 0, Previously indexed timestamp: 1498104813269
消费者平衡过程
消费者平衡(Consumer Rebalance)是指的是消费者重新加入消费组,并重新分配分区给消费者的过程。在以下情况下会引起消费者平衡操作:
- 新的消费者加入消费组
- 当前消费者从消费组退出(不管是异常退出还是正常关闭)
- 消费者取消对某个主题的订阅
- 订阅主题的分区增加(Kafka的分区数可以动态增加但是不能减少)
- broker宕机新的协调器当选
- 当消费者在
${session.timeout.ms}时间内还没有发送心跳请求,组协调器认为消费者已退出。
消费者自动平衡操作提供了消费者的高可用和高可扩展性,这样当我们增加或者减少消费者或者分区数的时候,不需要关心底层消费者和分区的分配关系。但是需要注意的是,在rebalancing过程中,由于需要给消费者重新分配分区,所以会出现在一个短暂时间内消费者不能拉取消息的状况。
NOTES
这里要特别注意最后一种情况,就是所谓的慢消费者(Slow Consumers)。如果没有在session.timeout.ms时间内收到心跳请求,协调者可以将慢消费者从组中移除。通常,如果消息处理比session.timeout.ms慢,就会成为慢消费者。导致两次poll()方法的调用间隔比session.timeout.ms时间长。由于心跳只在 poll()调用时才会发送(在0.10.1.0版本中, 客户端心跳在后台异步发送了),这就会导致协调者标记慢消费者死亡。
如果没有在session.timeout.ms时间内收到心跳请求,协调者标记消费者死亡并且断开和它的连接。
同时,通过向组内其他消费者的HeartbeatResponse中发送IllegalGeneration错误代码 触发rebalance操作。
在手动commit offset的模式下,要特别注意这个问题,否则会出现commit不上的情况。导致一直在重复消费。
Kafka的特点
- 消息顺序:保证每个partition内部的顺序,但是不保证跨partition的全局顺序。如果需要全局消息有序,topic只能有一个partition。
- consumer group:consumer group中的consumer并发获取消息,但是为了保证partition消息的顺序性,每个partition只会由一个consumer消费。因此consumer group中的consumer数量需要小于等于topic的partition个数。(如需全局消息有序,只能有一个partition,一个consumer)
- 同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。
- Producer Push消息,Client Pull消息模式: 一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用push模式。事实上,push模式和pull模式各有优劣。push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm或Spark Streaming这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
kafka的HA
Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务。若该Broker永远不能再恢复,亦或磁盘故障,则其上数据将丢失。而Kafka的设计目标之一即是提供数据持久化,同时对于分布式系统来说,尤其当集群规模上升到一定程度后,一台或者多台机器宕机的可能性大大提高,对Failover要求非常高。因此,Kafka从0.8开始提供High Availability机制。主要表现在Data Replication和Leader Election两方面。
Data Replication
Kafka从0.8开始提供partition级别的replication,replication的数量可在$KAFKA_HOME/config/server.properties 中配置:
default.replication.factor = 1
该 Replication与leader election配合提供了自动的failover机制。replication对Kafka的吞吐率是有一定影响的,但极大的增强了可用性。默认情况下,Kafka的replication数量为1。 每个partition都有一个唯一的leader,所有的读写操作都在leader上完成,follower批量从leader上pull数据。一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。follower上的日志和其leader上的完全一样。
需要注意的是,replication factor并不会影响consumer的吞吐率测试,因为consumer只会从每个partition的leader读数据,而与replicaiton factor无关。同样,consumer吞吐率也与同步复制还是异步复制无关。
Leader Election
引入Replication之后,同一个Partition可能会有多个副本(Replica),而这时需要在这些副本之间选出一个Leader,Producer和Consumer只与这个Leader副本交互,其它Replica作为Follower从Leader中复制数据。注意,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),并不提供任何读写服务,系统更加简单且高效。
思考 为什么follower副本不提供读写,只做冷备?
follwer副本不提供写服务这个比较好理解,因为如果follower也提供写服务的话,那么就需要在所有的副本之间相互同步。n个副本就需要 nxn 条通路来同步数据,如果采用异步同步的话,数据的一致性和有序性是很难保证的;而采用同步方式进行数据同步的话,那么写入延迟其实是放大n倍的,反而适得其反。
那么为什么不让follower副本提供读服务,减少leader副本的读压力呢?这个除了因为同步延迟带来的数据不一致之外,不同于其他的存储服务(如ES,MySQL),Kafka的读取本质上是一个有序的消息消费,消费进度是依赖于一个叫做offset的偏移量,这个偏移量是要保存起来的。如果多个副本进行读负载均衡,那么这个偏移量就不好确定了。
TIPS
Kafka的leader副本类似于ES的primary shard,follower副本相对于ES的replica。ES也是一个index有多个shard(相对于Kafka一个topic有多个partition),shard又分为primary shard和replicition shard,其中primary shard用于提供读写服务(sharding方式跟MySQL非常类似:shard = hash(routing) % number_of_primary_shards。但是ES引入了协调节点(coordinating node) 的角色,实现对客户端透明。),而replication shard只提供读服务(这里跟Kafka一样,ES会等待relication shard返回成功才最终返回给client)。
有传统MySQL分库分表经验的同学一定会觉得这个过程是非常相似的,就是一个 sharding + replication 的数据架构,只是通过client(SDK)或者coordinator对你透明了而已。
Propagate消息
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了 ISR (in-sync replicas) 中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加 HW( High-Watermark) 并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
Consumer读消息也是从Leader读取,只有被commit过的消息(offset低于HW的消息)才会暴露给Consumer。
Kafka Replication的数据流如下图所示:
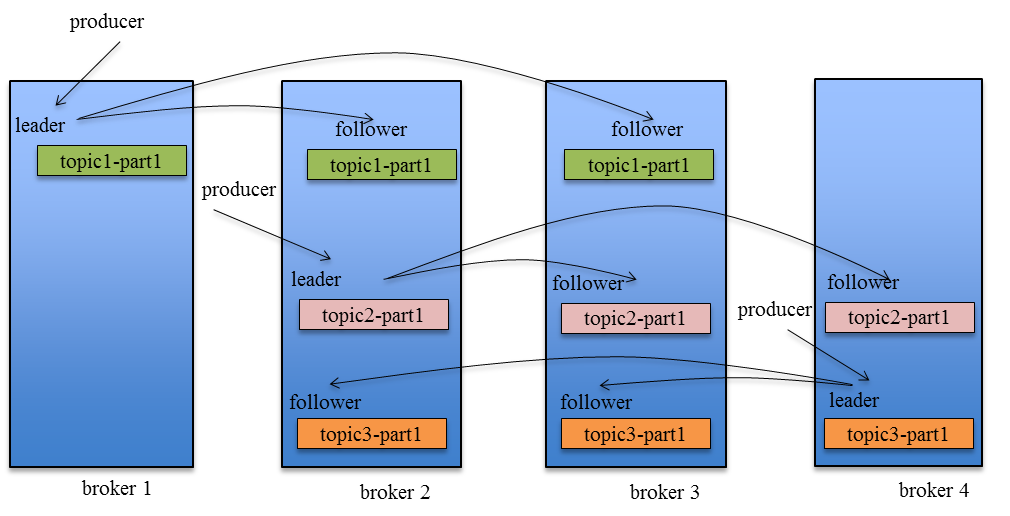
关于这方面的内容比较多而且复杂,这里就不展开了,这篇文章写的很好,有兴趣的同学可以学习 Kafka设计解析(二):Kafka High Availability (上)。
Kafka的几个游标(偏移量/offset)
下面这张图非常简单明了的显示kafka的所有游标(https://rongxinblog.wordpress.com/2016/07/29/kafka-high-watermark/):
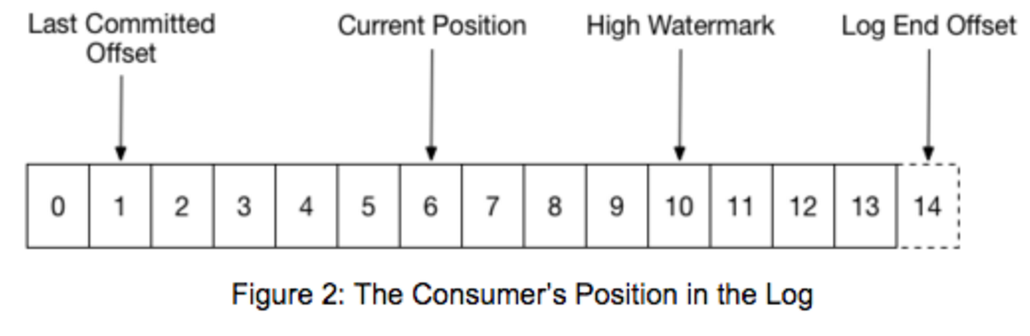
下面简单的说明一下:
0、ISR
In-Sync Replicas list,顾名思义,就是跟leader “保存同步” 的Replicas。“保持同步”的含义有些复杂,在0.9版本,broker的参数replica.lag.time.max.ms用来指定ISR的定义,如果leader在这么长时间没收到follower的拉取请求,或者在这么长时间内,follower没有fetch到leader的log end offset,就会被leader从ISR中移除。ISR是个很重要的指标,controller选取partition的leader replica时会使用它,leader需要维护ISR列表,因此leader选取ISR后会把结果记到Zookeeper上。
在需要选举leader的场景下,leader和ISR是由controller决定的。在选出leader以后,ISR是leader决定。如果谁是leader和ISR只存在于ZK上,那么每个broker都需要在Zookeeper上监听它host的每个partition的leader和ISR的变化,这样效率比较低。如果不放在Zookeeper上,那么当controller fail以后,需要从所有broker上重新获得这些信息,考虑到这个过程中可能出现的问题,也不靠谱。所以leader和ISR的信息存在于Zookeeper上,但是在变更leader时,controller会先在Zookeeper上做出变更,然后再发送LeaderAndIsrRequest给相关的broker。这样可以在一个LeaderAndIsrRequest里包括这个broker上有变动的所有partition,即batch一批变更新信息给broker,更有效率。另外,在leader变更ISR时,会先在Zookeeper上做出变更,然后再修改本地内存中的ISR。
1、Last Commited Offset
Consumer最后提交的位置,这个位置会保存在一个特殊的topic:_consumer_offsets 中。
2、Current Position
Consumer当前读取的位置,但是还没有提交给broker。提交之后就变成Last Commit Offset。
3、High Watermark(HW)
这个offset是所有ISR的LEO的最小位置(minimum LEO across all the ISR of this partition),consumer不能读取超过HW的消息,因为这意味着读取到未完全同步(因此没有完全备份)的消息。换句话说就是:HW是所有ISR中的节点都已经复制完的消息.也是消费者所能获取到的消息的最大offset(注意,并不是所有replica都一定有这些消息,而只是ISR里的那些才肯定会有)。
随着follower的拉取进度的即时变化,HW是随时在变化的。follower总是向leader请求自己已有messages的下一个offset开始的数据,因此当follower发出了一个fetch request,要求offset为A以上的数据,leader就知道了这个follower的log end offset至少为A。此时就可以统计下ISR里的所有replica的LEO是否已经大于了HW,如果是的话,就提高HW。同时,leader在fetch本地消息给follower时,也会在返回给follower的reponse里附带自己的HW。这样follower也就知道了leader处的HW(但是在实现中,follower获取的只是读leader本地log时的HW,并不能保证是最新的HW)。但是leader和follower的HW是不同步的,follower处记的HW可能会落后于leader。
Hight Watermark Checkpoint
由于HW是随时变化的,如果即时更新到Zookeeper,会带来效率的问题。而HW是如此重要,因此需要持久化,ReplicaManager就启动了单独的线程定期把所有的partition的HW的值记到文件中,即做highwatermark-checkpoint。
4、Log End Offset(LEO)
这个很好理解,就是当前的最新日志写入(或者同步)位置。
Kafka客户端
Kafka支持JVM语言(java、scala),同是也提供了高性能的C/C++客户端,和基于librdkafka封装的各种语言客户端。如,Python客户端: confluent-kafka-python 。Python客户端还有纯python实现的:kafka-python。
下面是Python例子(以confluent-kafka-python为例):
Producer:
from confluent_kafka import Producer
p = Producer({'bootstrap.servers': 'mybroker,mybroker2'})
for data in some_data_source:
p.produce('mytopic', data.encode('utf-8'))
p.flush()
Consumer:
from confluent_kafka import Consumer, KafkaError
c = Consumer({'bootstrap.servers': 'mybroker', 'group.id': 'mygroup',
'default.topic.config': {'auto.offset.reset': 'smallest'}})
c.subscribe(['mytopic'])
running = True
while running:
msg = c.poll()
if not msg.error():
print('Received message: %s' % msg.value().decode('utf-8'))
elif msg.error().code() != KafkaError._PARTITION_EOF:
print(msg.error())
running = False
c.close()
跟普通的消息队列使用基本是一样的。
Kafka的offset管理
kafka读取消息其实是基于offset来进行的,如果offset出错,就可能出现重复读取消息或者跳过未读消息。在0.8.2之前,kafka是将offset保存在ZooKeeper中,但是我们知道zk的写操作是很昂贵的,而且不能线性拓展,频繁的写入zk会导致性能瓶颈。所以在0.8.2引入了Offset Management,将这个offset保存在一个 compacted kafka topic(_consumer_offsets),Consumer通过发送OffsetCommitRequest请求到指定broker(偏移量管理者)提交偏移量。这个请求中包含一系列分区以及在这些分区中的消费位置(偏移量)。偏移量管理者会追加键值(key-value)形式的消息到一个指定的topic(__consumer_offsets)。key是由consumerGroup-topic-partition组成的,而value是偏移量。同时为了提供性能,内存中也会维护一份最近的记录,这样在指定key的情况下能快速的给出OffsetFetchRequests而不用扫描全部偏移量topic日志。如果偏移量管理者因某种原因失败,新的broker将会成为偏移量管理者并且通过扫描偏移量topic来重新生成偏移量缓存。
如何查看消费偏移量
0.9版本之前的Kafka提供了kafka-consumer-offset-checker.sh脚本,可以用来查看某个消费组对一个或者多个topic的消费者消费偏移量情况,该脚本调用的是kafka.tools.Consumer.OffsetChecker。0.9版本之后已不再建议使用该脚本了,而是建议使用kafka-consumer-groups.sh脚本,该脚本调用的是kafka.admin.ConsumerGroupCommand。这个脚本其实是对消费组进行管理,不只是查看消费组的偏移量。这里只介绍最新的kafka-consumer-groups.sh脚本使用。
用ConsumerGroupCommand工具,我们可以使用list,describe,或delete消费者组。
例如,要列出所有主题中的所有消费组信息,使用list参数:
$ bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --list
test-consumer-group
要查看某个消费组当前的消费偏移量则使用describe参数:
$ bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --describe --group test-consumer-group
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
test-consumer-group test-foo 0 1 3 2 consumer-1_/127.0.0.1
NOTES
该脚本只支持删除不包括任何消费组的消费组,而且只能删除消费组为老版本消费者对应的消费组(即分组元数据存储在zookeeper的才有效),因为这个脚本删除操作的本质就是删除ZK中对应消费组的节点及其子节点而已。
如何管理消费偏移量
上面介绍了通过脚本工具方式查询Kafka消费偏移量。事实上,我们也可以通过API的方式查询消费偏移量。
Kafka消费者API提供了两个方法用于查询消费者消费偏移量的操作:
- committed(TopicPartition partition): 该方法返回一个
OffsetAndMetadata对象,通过它可以获取指定分区已提交的偏移量。 - position(TopicPartition partition): 该方法返回下一次拉取位置的position。
除了查看消费偏移量,有些时候我们需要人为的指定offset,比如跳过某些消息,或者redo某些消息。在0.8.2之前,offset是存放在ZK中,只要用ZKCli操作ZK就可以了。但是在0.8.2之后,offset默认是存放在kafka的__consumer_offsets队列中,只能通过API修改了:
Class KafkaConsumer<K,V> Kafka allows specifying the position using seek(TopicPartition, long) to specify the new position. Special methods for seeking to the earliest and latest offset the server maintains are also available ( seekToBeginning(TopicPartition…) and seekToEnd(TopicPartition…) respectively).
参考文档: Kafka Consumer Offset Management
Kafka消费者API提供了重置消费偏移量的方法:
- seek(TopicPartition partition, long offset): 该方法用于将消费起始位置重置到指定的偏移量位置。
- seekToBeginning(): 从消息起始位置开始消费,对应偏移量重置策略
auto.offset.reset=earliest。 - seekToEnd(): 从最新消息对应的位置开始消费,也就是说等待新的消息写入后才开始拉取,对应偏移量重置策略是
auto.offset.reset=latest。
当然前提你得知道要重置的offset的位置。一种方式就是根据时间戳获取对应的offset。再seek过去。
部署和配置
Kafka是用Scala写的,所以只要安装了JRE环境,运行非常简单。直接下载官方编译好的包,解压配置一下就可以直接运行了。
kafka配置
配置文件在config目录下的server.properties,关键配置如下(有些属性配置文件中默认没有,需自己添加):
- broker.id:Kafka集群中每台机器(称为broker)需要独立不重的id
- port:监听端口
- delete.topic.enable:设为true则允许删除topic,否则不允许
- message.max.bytes:允许的最大消息大小,默认是1000012(1M),建议调到到10000012(10M)。
- replica.fetch.max.bytes: 同上,默认是1048576,建议调到到10048576。
- log.dirs:Kafka数据文件的存放目录,注意不是日志文件。可以配置为:/home/work/kafka/data/kafka-logs
- log.cleanup.policy:过期数据清除策略,默认为delete,还可设为compact
- log.retention.hours:数据过期时间(小时数),默认是1073741824,即一周。过期数据用log.cleanup.policy的规则清除。可以用log.retention.minutes配置到分钟级别。
- log.segment.bytes:数据文件切分大小,默认是1073741824(1G)。
- retention.check.interval.ms:清理线程检查数据是否过期的间隔,单位为ms,默认是300000,即5分钟。
- zookeeper.connect:负责管理Kafka的zookeeper集群的机器名:端口号,多个用逗号分隔
TIPS 发送和接收大消息
需要修改如下参数:
- broker:message.max.bytes & replica.fetch.max.bytes
- consumer:fetch.message.max.bytes
更多参数的详细说明见官方文档:http://kafka.apache.org/documentation.html#brokerconfigs
ZK配置和启动
然后先确保ZK已经正确配置和启动了。Kafka自带ZK服务,配置文件在config/zookeeper.properties文件,关键配置如下:
dataDir=/home/work/kafka/data/zookeeper
clientPort=2181
maxClientCnxns=0
tickTime=2000
initLimit=10
syncLimit=5
server.1=nj03-bdg-kg-offline-01.nj03:2888:3888
server.2=nj03-bdg-kg-offline-02.nj03:2888:3888
server.3=nj03-bdg-kg-offline-03.nj03:2888:3888
NOTES Zookeeper集群部署
ZK的集群部署要做两件事情:
- 分配serverId: 在dataDir目录下创建一个myid文件,文件中只包含一个1到255的数字,这就是ZK的serverId。
- 配置集群:格式为
server.{id}={host}:{port}:{port},其中{id}就是上面提到的ZK的serverId。
然后启动:bin/zookeeper-server-start.sh -daemon config/zookeeper.properties。
启动kafka
然后可以启动Kafka:JMX_PORT=8999 bin/kafka-server-start.sh -daemon config/server.properties,非常简单。
TIPS
我们在启动命令中增加了JMX_PORT=8999环境变量,这样可以暴露JMX监控项,方便监控。
Kafka监控和管理
不过不像RabbitMQ,或者ActiveMQ,Kafka默认并没有web管理界面,只有命令行语句,不是很方便,不过可以安装一个,比如,Yahoo的 Kafka Manager: A tool for managing Apache Kafka。它支持很多功能:
- Manage multiple clusters
- Easy inspection of cluster state (topics, consumers, offsets, brokers, replica distribution, partition distribution)
- Run preferred replica election
- Generate partition assignments with option to select brokers to use
- Run reassignment of partition (based on generated assignments)
- Create a topic with optional topic configs (0.8.1.1 has different configs than 0.8.2+)
- Delete topic (only supported on 0.8.2+ and remember set delete.topic.enable=true in broker config)
- Topic list now indicates topics marked for deletion (only supported on 0.8.2+)
- Batch generate partition assignments for multiple topics with option to select brokers to use
- Batch run reassignment of partition for multiple topics
- Add partitions to existing topic
- Update config for existing topic
- Optionally enable JMX polling for broker level and topic level metrics.
- Optionally filter out consumers that do not have ids/ owners/ & offsets/ directories in zookeeper.
安装过程蛮简单的,就是要下载很多东东,会很久。具体参见: kafka manager安装。不过这些管理平台都没有权限管理功能。
需要注意的是,Kafka Manager的conf/application.conf配置文件里面配置的kafka-manager.zkhosts是为了它自身的高可用,而不是指向要管理的Kafka集群指向的zkhosts。所以不要忘记了手动配置要管理的Kafka集群信息(主要是配置名称,和zk地址)。Install and Evaluation of Yahoo’s Kafka Manager。
Kafka Manager主要是提供管理界面,监控的话还要依赖于其他的应用,比如:
- Burrow: Kafka Consumer Lag Checking. Linkedin开源的cusumer log监控,go语言编写,貌似没有界面,只有HTTP API,可以配置邮件报警。
- Kafka Offset Monitor: A little app to monitor the progress of kafka consumers and their lag wrt the queue.
这两个应用的目的都是监控Kafka的offset。
删除主题
删除Kakfa主题,一般有如下两种方式:
1、手动删除各个节点${log.dir}目录下该主题分区文件夹,同时登陆ZK客户端删除待删除主题对应的节点,主题元数据保存在/brokers/topics和/config/topics节点下。
2、执行kafka-topics.sh脚本执行删除,若希望通过该脚本彻底删除主题,则需要保证在启动Kafka时加载的 server.properties 文件中配置 delete.topic.enable=true,该配置项默认为false。否则执行该脚本并未真正删除topic,而是在ZK的/admin/delete_topics目录下创建一个与该待删除主题同名的topic,将该主题标记为删除状态而已。
kafka-topic –delete –zookeeper server-1:2181,server-2:2181 –topic test`
执行结果:
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
此时若希望能够彻底删除topic,则需要通过手动删除相应文件及节点。当该配置项为true时,则会将该主题对应的所有文件目录以及元数据信息删除。
过期数据自动清除
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。可以通过配置$KAFKA_HOME/config/server.properties ,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据:
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
# By default the log cleaner is disabled and the log retention policy will default to
# just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs
# can then be marked for log compaction.
log.cleaner.enable=false
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只与磁盘以及具体的需求有关。
Kafka的一些问题
1、只保证单个主题单个分区内的消息有序,但是不能保证单个主题所有分区消息有序。如果应用严格要求消息有序,那么kafka可能不大合适。
2、消费偏移量由消费者跟踪和提交,但是消费者并不会经常把这个偏移量写会kafka,因为broker维护这些更新的代价很大,这会导致异常情况下消息可能会被多次消费或者没有消费。
具体分析如下:消息可能已经被消费了,但是消费者还没有像broker提交偏移量(commit offset)确认该消息已经被消费就挂掉了,接着另一个消费者又开始处理同一个分区,那么它会从上一个已提交偏移量开始,导致有些消息被重复消费。但是反过来,如果消费者在批处理消息之前就先提交偏移量,但是在处理消息的时候挂掉了,那么这部分消息就相当于『丢失』了。通常来说,处理消息和提交偏移量很难构成一个原子性操作,因此无法总是保证所有消息都刚好只被处理一次。
3、主题和分区的数目有限
Kafka集群能够处理的主题数目是有限的,达到1000个主题左右时,性能就开始下降。这些问题基本上都跟Kafka的基本实现决策有关。特别是,随着主题数目增加,broker上的随机IO量急剧增加,因为每个主题分区的写操作实际上都是一个单独的文件追加(append)操作。随着分区数目增加,问题越来越严重。如果Kafka不接管IO调度,问题就很难解决。
当然,一般的应用都不会有这么大的主题数和分区数要求。但是如果将单个Kafka集群作为多租户资源,这个时候这个问题就会暴露出来。
4、手动均衡分区负载
Kafka的模型非常简单,一个主题分区全部保存在一个broker上,可能还有若干个broker作为该分区的副本(replica)。同一分区不在多台机器之间分割存储。随着分区不断增加,集群中有的机器运气不好,会正好被分配几个大分区。Kafka没有自动迁移这些分区的机制,因此你不得不自己来。监控磁盘空间,诊断引起问题的是哪个分区,然后确定一个合适的地方迁移分区,这些都是手动管理型任务,在Kafka集群环境中不容忽视。
如果集群规模比较小,数据所需的空间较小,这种管理方式还勉强奏效。但是,如果流量迅速增加或者没有一流的系统管理员,那么情况就完全无法控制。
注意:如果向集群添加新的节点,也必须手动将数据迁移到这些新的节点上,Kafka不会自动迁移分区以平衡负载量或存储空间的。
5、follow副本(replica)只充当冷备(解决HA问题),无法提供读服务
不像ES,replica shard是同时提供读服务,以缓解master的读压力。kafka因为读服务是有状态的(要维护commited offset),所以follow副本并没有参与到读写服务中。只是作为一个冷备,解决单点问题。
6、只能顺序消费消息,不能随机定位消息,出问题的时候不方便快速定位问题
这其实是所有以消息系统作为异步RPC的通用问题。假设发送方发了一条消息,但是消费者说我没有收到,那么怎么排查呢?消息队列缺少随机访问消息的机制,如根据消息的key获取消息。这就导致排查这种问题不大容易。
推荐阅读
- Centralized Logging Solutions Overview
- Logging and Aggregation at Quora
- ELK在广告系统监控中的应用 及 Elasticsearch简介
- Centralized Logging
- Centralized Logging Architecture 强烈推荐!