线程
线程VS进程
lightweight processes
fork is expensive. Memory is copied from the parent to the child, all descriptors are duplicated in the child, and so on. Current implementations use a technique called copy-on-write, which avoids a copy of the parent’s data space to the child until the child needs its own copy. But, regardless of this optimization, fork is expensive.
IPC is required to pass information between the parent and child after the fork. Passing information from the parent to the child before the fork is easy, since the child starts with a copy of the parent’s data space and with a copy of all the parent’s descriptors. But, returning information from the child to the parent takes more work.
同个进程中的所有线程共享如下数据:
- Process instructions
- Most data
- Open files (e.g., descriptors)
- Signal handlers and signal dispositions
- Current working directory
- User and group IDs
但是每个线程有自己的私有数据:
- Thread ID
- Set of registers, including program counter and stack pointer
- Stack (for local variables and return addresses)
- errno
- Signal mask
- Priority
基本线程操作
1. 创建线程
Thread thread = new Thread(); // Creating a thread
thread.start(); // start the thread
但是上面的代码没有任何意思,因为新创建的子线程没有执行任何代码就退出了。我们要为它指定要执行的代码,在Java中有如下两种方式:
1. Thread Subclass
创建Thread的子类,重载run()方法
public class MyThread extends Thread {
public void run(){
System.out.println("MyThread running");
}
}
MyThread myThread = new MyThread();
myTread.start();
在Java中,创建匿名子类很常见:
Thread thread = new Thread(){
public void run(){
System.out.println("Thread Running");
}
}
thread.start();
2. Runnable Interface Implemention (Prefer)
传递一个实现了Runnable接口的对象给线程构造函数
public class MyRunnable implements Runnable {
public void run(){
System.out.println("MyRunnable running");
}
}
Thread thread = new Thread(new MyRunnable());
thread.start();
同样,可以创建匿名runable对象:
Runnable myRunnable = new Runnable(){
public void run(){
System.out.println("Runnable running");
}
}
Thread thread = new Thread(myRunnable);
thread.start();
注意
-
run() VS start()
Thread newThread = new Thread(MyRunnable()); thread.run(); //should be start();run()方法是在当前的线程执行,而不是新创建的线程!!!(it is NOT executed by the new thread you just created. Instead the run() method is executed by the thread that created the thread. In other words, the thread that executed the above two lines of code.)
-
Java的线程可以有名称
Thread thread = new Thread("New Thread") // ... MyRunnable runnable = new MyRunnable(); Thread thread = new Thread(runnable, "New Thread"); // ... System.out.println(thread.getName()); String threadName = Thread.currentThread().getName(); -
pthread的线程创建函数
int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*func) (void *), void *arg);
2. 等待线程结束
int pthread_join (pthread_t tid, void ** status);
3. 线程间通信
1. 共享变量
由于线程之间共享同一个进程空间,所以只要他们引用同一个变量,就可以通过读写这个变量实现信息交流了。不过要注意并发访问问题。
2. wait(), nofity(), notifyAll()
public class MonitorObject{
}
public class MyWaitNotify{
MonitorObject myMonitorObject = new MonitorObject();
public void doWait(){
synchronized(myMonitorObject){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
}
public void doNotify(){
synchronized(myMonitorObject){
myMonitorObject.notify();
}
}
}
As you can see both the waiting and notifying thread calls wait() and notify() from within a synchronized block. This is mandatory! A thread cannot call wait(), notify() or notifyAll() without holding the lock on the object the method is called on. If it does, an IllegalMonitorStateException is thrown.
线程池
线程池可以看成是一个待执行任务队列和一个执行线程队列的集合。我们可以往线程池里面扔任务,线程池中的执行线程会从任务队列中获取任务执行。
下面是一个简单的线程池实现:
public class ThreadPool {
private BlockingQueue taskQueue = null;
private List<PoolThread> threads = new ArrayList<PoolThread>();
private boolean isStopped = false;
public ThreadPool(int noOfThreads, int maxNoOfTasks){
taskQueue = new BlockingQueue(maxNoOfTasks);
for(int i=0; i<noOfThreads; i++){
threads.add(new PoolThread(taskQueue));
}
for(PoolThread thread : threads){
thread.start();
}
}
public void synchronized execute(Runnable task){
if(this.isStopped) throw
new IllegalStateException("ThreadPool is stopped");
this.taskQueue.enqueue(task);
}
public synchronized void stop(){
this.isStopped = true;
for(PoolThread thread : threads){
thread.stop();
}
}
}
public class PoolThread extends Thread {
private BlockingQueue taskQueue = null;
private boolean isStopped = false;
public PoolThread(BlockingQueue queue){
taskQueue = queue;
}
public void run(){
while(!isStopped()){
try{
Runnable runnable = (Runnable) taskQueue.dequeue();
runnable.run();
} catch(Exception e){
//log or otherwise report exception,
//but keep pool thread alive.
}
}
}
public synchronized void stop(){
isStopped = true;
this.interrupt(); //break pool thread out of dequeue() call.
}
public synchronized void isStopped(){
return isStopped;
}
}
Java的ThreadPoolExecutor
ThreadPoolExecutor的完整构造方法的签名是:
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,
RejectedExecutionHandler handler);
这个函数的参数比较多,暴露了太多的实现细节,所以JDK又提供了Executors工程类,Executors类的底层实现便是ThreadPoolExecutor,它提供了几个工厂方法方便用户创建合适的线程池。
在JDK帮助文档中,有如此一段话:“强烈建议程序员使用较为方便的 Executors 工厂方法 Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)和 Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置。”
不过还是很有必要了解一下底层的东西:)
-
corePoolSize
核心线程数,核心线程会一直存活,即使没有任务需要处理。当线程数小于核心线程数时,即使现有的线程空闲,线程池也会优先创建新线程来处理任务,而不是直接交给现有的线程处理。 核心线程在allowCoreThreadTimeout被设置为true时会超时退出,默认情况下不会退出。
-
maxPoolSize
当线程数大于或等于核心线程,且任务队列已满时,线程池会创建新的线程,直到线程数量达到maxPoolSize。如果线程数已等于maxPoolSize,且任务队列已满,则已超出线程池的处理能力,线程池会拒绝处理任务而抛出异常。
-
keepAliveTime
当线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize。如果allowCoreThreadTimeout设置为true,则所有线程均会退出直到线程数量为0。
-
allowCoreThreadTimeout
是否允许核心线程空闲退出,默认值为false。
-
queueCapacity
任务队列容量。从maxPoolSize的描述上可以看出,任务队列的容量会影响到线程的变化,因此任务队列的长度也需要恰当的设置。
线程池按以下行为执行任务:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满
- 若线程数小于最大线程数,创建线程
- 若线程数等于最大线程数,抛出异常,拒绝任务
BlockingQueue
所有 BlockingQueue 都可用于传输和保持提交的任务。可以使用此队列与池大小进行交互:
- 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。(什么意思?如果当前运行的线程小于corePoolSize,则任务根本不会存放,添加到queue中,而是直接抄家伙(thread)开始运行)
- 如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
- 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
排队有三种通用策略:
- 直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
- 无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
- 有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
线程执行结果——Callable和Future
同步返回结果
Runable并不能返回执行结果。如果你想要线程执行完毕后返回执行结果,可以使用java.util.concurrent.Callable。
异步返回结果
在java中,异步操作往往喜欢返回一个Future对象,顾名思义,表示结果在未来的某个时刻才完成,虽然future是立马返回的,但是其实是一个未知的结果。调用方可以(需要)查询这个future对象,看是不是已经出结果了。其实是一种polling方式来的。
这些Future对象,一般都是实现java.util.concurrent.Future接口:
Future返回对象可以是Callable的返回值:
import java.util.concurrent.Callable;
public class MyCallable implements Callable<Long> {
@Override
public Long call() throws Exception {
long sum = 0;
for (long i = 0; i <= 100; i++) {
sum += i;
}
return sum;
}
}
public class CallableFutures {
private static final int NTHREDS = 10;
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(NTHREDS);
List<Future<Long>> list = new ArrayList<Future<Long>>();
for (int i = 0; i < 20000; i++) {
Callable<Long> worker = new MyCallable();
Future<Long> submit = executor.submit(worker);
list.add(submit);
}
long sum = 0;
System.out.println(list.size());
// now retrieve the result
for (Future<Long> future : list) {
try {
sum += future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
System.out.println(sum);
executor.shutdown();
}
}
JMM(Java内存模型)
- 可见性
- 访问控制
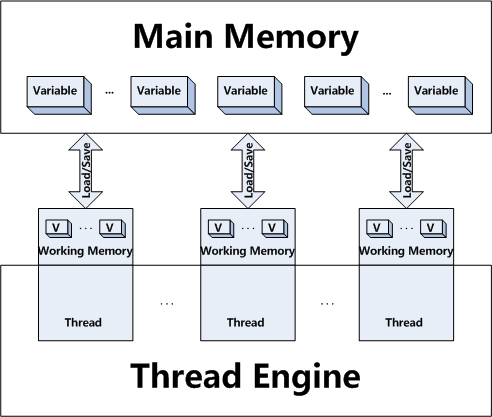
volatile
- 如果不声明volatile,变量装载到本地变量中,或者cpu cache中,多线程下很容易导致状态不一致。
- 声明了volatile,每次访问的都是主存中的数据,一致性能提升,但是还是不可靠的。
- volatile字段的访问效率很低,每次访问都需要十几个nano。大约为lock的1/3时间
CAS(Compare And Swap)
- CAS指令由硬件提供
- 并发程序设计实现的基础
- 486之后并不需要锁总线
- 基于MESI缓存一致性协议
lock和synchronized
- 保证代码块的不可重入
- 底层都是基于CAS实现的
- 通过jstack -l
获得jvm的线程信息和锁信息
参考资料
- Java Concurrency/Multithreading Tutorial
- java.util.concurrent - Java 5 Concurrency Utilities
- Multithreaded Servers in Java
- Java concurrency (multi-threading) - tutorial
- 并发编程网