背景
去年开始做知识图谱,从网站抓取到的数据经过清洗、抽取、消歧、挖掘等最后得到的图谱,需要以在线的形式提供给用户使用,这就需要一个图数据库了。为了避免重复造轮子,我们调研了很多开源的图数据库,像neo4j, Titan, OrientDB,Graph Engine(@Microsoft), Cayley, ArangoDB, 等等。具体可以参考笔者之前写的一篇文章:图存储引擎学习笔记。
遗憾的是这块不像RMDB,并没有一个winer,各有优缺点。本来想用Titan的,但是发现Titan的性能实在太差,而且更重要的是,代码非常复杂,不利于维护和扩展。最后我们觉得自己开发一个。但是我们并不打算从零开始构建一个图存储,而是借鉴了Titan的思想,做一个粘合层,底层的分布式存储和索引这块交给成熟的分布式NoSQL处理,这里我们选了Aerospike。
经过一两个月的开发,终于在最近完成第一版的功能。这里简单介绍一下我们的GraphDB。
图模型——Label Property Graph Model
- Vertex
- 用于表示实体(Entity)
- 有一个稳定的唯一的id
- 可以并且一般有一个label,表示实体类型,如Person,Product, etc.
- Vertex: id -> label, property*
- 其中lable决定该实体的schema,如Person, Product, etc. Schema对于在线系统只作为接口文档,存储是schema-less。
- Edge
- 用于表示关系(Relationship)
- SPO三元组,附加可选的k-v属性对
- Edge: (from_id, label, to_id) -> property*
- 其中label是边的类型,起到labeled edge的作用
- 关系具有双向性,可以根据这个同时建立反向关系,如:妻子 <=> 丈夫,兄弟 <=> 兄弟
- 关系可以由 (from_id, label, to_id) 唯一确定,关系id由这个生成
- Property
- 属性,k-v键值对
- Property: key -> value
- key永远是string类型,value可以是:
- Numeric
- String
- Boolean
- Lists of any other type of value
- 自定义类型(Json中的Map)
- Label
- 用于对节点和边进行归类
说明
- vertex label: neo4j的node可以有0个或者多个lable;titan则是0个或者1个,如果没有指定,会使用默认的label。出于性能考虑,GDB要求必须提供一个label。
- 属性理论上来说是可以有一些附加元信息的,如置信度,作者,来源等;Titan的Property of Property能够很好的支持这个功能;但是考虑到复杂性和需求的特殊性,这里不考虑。
- 这里不强制要求weighted edge,如果要表示关系的强弱程度(Weight of Edge),可以在边的properties中增加weight属性,可以用于关系检索时候的排序和截断。
- 关系也可能有别名,如: 妻子==老婆==夫人,由上层进行归一或者业务存储一个alias的property实现,GDB不处理这个。
接口
1、Graph接口
1、创建Graph(因为Aerospike现在不支持动态删除namespace,先不支持):
Graph g = new AerospikeGraph(String graphName, boolean loadIfExist);
2、加载已经存在的Graph:
Graph g = new AerospikeGraph(String graphName, boolean loadIfExist);
3、删除Graph(因为Aerospike现在不支持动态删除namespace,先不支持):
Graph.drop(graphName: String);
4、清空数据:
// 清空整个图数据
graph.dropData();
// 清空某个label的数据
graph.dropData(String label);
说明
- 目前只有一个实现,就是基于Aerospike实现的AerospikeGraph。
- Graph暂时只有一个GraphName,后面应该是有一个配置信息的,对应Aerospike的Namespace配置persistence、replication-factor等
- 因为Aerospike暂时(<=3.12版本)不支持动态创建和删除namespace,所以我们这里也先不支持动态创建和删除Graph [TODO]
2、索引接口
1、创建索引
public Index createIndex(String label, String path, IndexType indexType);
public Index createArrayIndex(String label, String path, IndexType indexType);
public Index createIndex(String label, String path, IndexType indexType, boolean arrayIndex);
public Index[] createIndex(Index...indexes);
说明
- 目前支持精确匹配和范围查询
- 支持嵌套属性索引,需要用attribute path指定,如
name/last - 支持数组类型的索引,如tags检索就是最常见的需求
- 后续会支持Geo类型索引
- 后续会支持全文检索
2、删除索引:
// 删除所有索引
public void dropIndex();
// 删除指定索引
public void dropIndex(String label, String path);
// 批量删除指定索引
public void dropIndex(Index...indexes);
3、重建索引(会对数据进行一次扫描以建立索引)
public Index reIndex(String label, String path, IndexType indexType);
public Index reIndex(String label, String path, IndexType indexType, boolean arrayIndex);
// 批量重新构建索引(多个索引构建性能会比逐个构建好很多)
public Index[] reIndex(Index...indexes);
3、实体接口
1、添加实体:
public void addVertex(Vertex vertex);
public void addVertex(String label, String key, Property...properties);
public void addVertex(ID id, Property...properties);
public void addVertex(Document data); // json 数据
2、更新实体(允许局部更新,删除某个属性请将其value设置为null):
public void updateVertex(String label, String key, Property...properties);
public void updateVertex(String label, String key, Document data);
3、删除实体(同时删除顶点关联的边):
public void deleteVertex(String label, String key);
4、关系接口
1、添加关系:
public void addEdge(Edge edge);
public void addEdge(String label, String key, ID from, ID to, boolean bidirection, Property...properties);
public void addEdge(String label, ID from, ID to, Property...properties);
public void addEdge(String label, ID from, ID to, boolean bidirection, Property...properties);
public void addEdge(String label, String key, ID from, ID to, Document data);
public void addEdge(String label, String key, ID from, ID to, boolean bidirection, Document data);
public void addEdge(String label, ID from, ID to, Document data);
public void addEdge(String label, ID from, ID to, boolean bidirection, Document data);
2、更新关系(支持部分更新):
public void updateEdge(String label, ID from, ID to, Property...properties);
public void updateEdge(String label, String key, Property...properties);
public void updateEdge(String label, ID from, ID to, Document data);
public void updateEdge(String label, String key, Document data);
3、删除关系:
public void deleteEdge(String label, String key);
public void deleteEdge(String label, ID from, ID to);
5、图检索
1、根据ID获取顶点和边
public Vertex getVertex(ID id);
public Vertex getVertex(String label, String key);
public Edge getEdge(ID id);
public Edge getEdge(String label, String key);
public Edge getEdge(String label, ID from, ID to);
2、图遍历:提供Gremlin图检索查询语言
public Query V(String label);
public Query E(String label);
其中Query定义如下:
package com.baidu.bdg.kg.gdb.query;
import java.util.List;
import java.util.Map;
import com.baidu.bdg.kg.gdb.Graph;
import com.baidu.bdg.kg.gdb.model.Document;
import com.baidu.bdg.kg.gdb.model.DocumentType;
import com.baidu.bdg.kg.gdb.model.ID;
/**
* <pre>
* Graph Query接口
* </pre>
*
* @author arganzheng
*
*/
public interface Query {
/*
* *****************************************************
*
* builder
*
* *****************************************************
*/
public Query setGraph(Graph graph);
public Query label(String label);
public Query key(String...keys);
public Query id(ID...ids);
public Query has(String key, Predicate predicate, Object condition);
public Query has(String key, Object value);
public Query hasNot(String key, Object value);
public Query interval(String key, Comparable<?> startValue, Comparable<?> endValue);
public Query limit(int limit);
public Query orderBy(String key);
public Query orderBy(String key, Order order);
public Query addOrder(String property, Order order);
/**
* 选择返回的字段,默认返回所有字段
*
* @param properties
*/
public Query values(String...properties);
// DocumentType => Vertex
public Query V();
// DocumentType => Edge
public Query E();
/*
* *****************************************************
*
* execute query
*
* *****************************************************
*/
public DocumentIterator vertices();
public DocumentIterator edges();
public DocumentIterator execute();
/**
* Whether the given element matches the conditions of this query.
*
* Used for result filtering if the result set returned by the query executor is not fitted.
*
* @param document
* @return
*/
public boolean match(Document document);
/*
* *****************************************************
*
* query traversal
*
* *****************************************************
*/
/**
* Gets the outgoing edges to the vertex.
*
* @return
*/
public Query outE();
/**
* Gets the outgoing edges to the vertex.
*
* @return
*/
public Query outE(String label);
/**
* Get both outgoing tail vertex of the edge.
*
* @return
*/
public Query outV();
/**
* Get both outgoing tail vertex of the edge.
*
* @return
*/
public Query outV(String label);
/**
* Gets the out adjacent vertices to the vertex.
*
* @return
*/
public Query out();
/**
* Gets the out adjacent vertices to the vertex.
*
* @return
*/
public Query out(String label);
/**
* Gets the in adjacent vertices to the vertex.
*
* @return
*/
public Query in();
/**
* Gets the in adjacent vertices to the vertex.
*
* @return
*/
public Query in(String label);
/**
* Gets the ingoing edges to the vertex.
*
* @return
*/
public Query inE();
/**
* Gets the ingoing edges to the vertex.
*
* @return
*/
public Query inE(String label);
/**
* Get both ingoing tail vertex of the edge.
*
* @return
*/
public Query inV();
/**
* Get both ingoing tail vertex of the edge.
*
* @return
*/
public Query inV(String label);
/*
* *****************************************************
*
* getter
*
* *****************************************************
*/
public Graph getGraph();
public String getGraphName();
public String getLabel();
public OrderList getOrderList();
public int getLimit();
public List<String> getSelectedFields();
public List<String> getKeys();
public Map<String, List<ID>> getIds();
public boolean hasIds();
public DocumentType getDocumentType();
public List<Condition<Document>> getConditions();
}
说明
- 目前只在java client提供类似于Gremlin的DSL查询语法。没有多语言SDK,也没有提供灵活的字符串查询语句,如Gremlin。这部分涉及到语法解析,实现起来比较复杂,在我们后面的功能排期中。现阶段非java业务接入,可以考虑提供python SDK,或者提供定制的HTTP API(需要开发)。
使用例子
1、创建图谱
以Titan的神图谱为例:
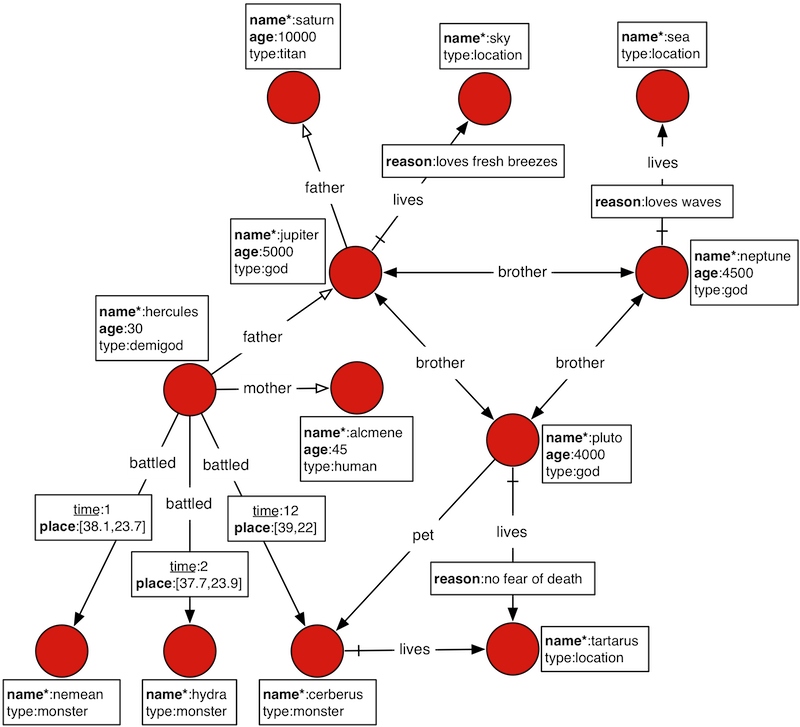
/**
* <pre>
* build the god family as Titan does.
* @see http://s3.thinkaurelius.com/docs/titan/1.0.0/getting-started.html
* </pre>
*/
@Test
public void testBuildGraphOfTheGodFamily() {
// create index
graph.createIndex("titan", "name", IndexType.STRING);
graph.createIndex("titan", "age", IndexType.NUMERIC);
graph.createIndex("god", "name", IndexType.STRING);
graph.createIndex("god", "age", IndexType.NUMERIC);
graph.createIndex("location", "name", IndexType.STRING);
graph.createIndex("monster", "name", IndexType.STRING);
graph.createIndex("lives", "reason", IndexType.STRING);
graph.createIndex("battled", "time", IndexType.NUMERIC);
// add vertex, here we use name as vertex key
graph.addVertex(new Vertex("titan", "saturn").addProperties("name", "saturn", "age", 10000));
graph.addVertex(new Vertex("location", "sky").addProperties("name", "sky"));
graph.addVertex(new Vertex("location", "sea").addProperties("name", "sea"));
graph.addVertex(new Vertex("god", "jupiter").addProperties("name", "jupiter", "age", 5000));
graph.addVertex(new Vertex("god", "neptune").addProperties("name", "neptune", "age", 4500));
graph.addVertex(new Vertex("demigod", "hercules").addProperties("name", "hercules", "age", 30));
graph.addVertex(new Vertex("human", "alcmene").addProperties("name", "alcmene", "age", 45));
graph.addVertex(new Vertex("god", "pluto").addProperties("name", "pluto", "age", 4000));
graph.addVertex(new Vertex("monster", "nemean").addProperties("name", "nemean"));
graph.addVertex(new Vertex("monster", "hydra").addProperties("name", "hydra"));
graph.addVertex(new Vertex("monster", "cerberus").addProperties("name", "cerberus"));
graph.addVertex(new Vertex("location", "tartarus").addProperties("name", "tartarus"));
// add edges
graph.addEdge("father", new ID("god", "jupiter"), new ID("titan", "saturn"));
graph.addEdge("lives", new ID("god", "jupiter"), new ID("location", "sky"), new Property("reason",
"loves fresh breezes"));
graph.addEdge("lives", new ID("god", "neptune"), new ID("location", "sea"), new Property("reason",
"loves wares"));
graph.addEdge("brother", new ID("god", "jupiter"), new ID("god", "neptune"), true);
graph.addEdge("brother", new ID("god", "jupiter"), new ID("god", "pluto"), true);
graph.addEdge("brother", new ID("god", "neptune"), new ID("god", "pluto"), true);
graph.addEdge("father", new ID("demigod", "hercules"), new ID("god", "jupiter"));
graph.addEdge("mother", new ID("demigod", "pluto"), new ID("human", "jupiter"));
graph.addEdge("battled", new ID("demigod", "hercules"), new ID("monster", "nemean"), new Property("time", 1));
graph.addEdge("battled", new ID("demigod", "hercules"), new ID("monster", "hydra"), new Property("time", 2));
graph.addEdge("battled", new ID("demigod", "hercules"), new ID("monster", "cerberus"), //
new Property("time", 12));
graph.addEdge("lives", new ID("god", "pluto"), new ID("location", "tartarus"), new Property("reason",
"no fear of death"));
graph.addEdge("pet", new ID("god", "pluto"), new ID("monster", "cerberus"));
graph.addEdge("lives", new ID("monster", "cerberus"), new ID("location", "tartarus"));
}
2、json方式加载数据
对于离线已经用JSON保存的数据来说,这种加载方式会简单很多。
@Test
public void testAddVertexWithJson() throws IOException {
String label = "test";
String filePath = this.getClass().getClassLoader().getResource("data/product.json").getFile();
File file = new File(filePath);
String productJsonData = Files.asCharSource(file, Charsets.UTF_8).read();
Document doc = Document.fromJson(productJsonData);
Vertex v = new Vertex(doc);
v.setLabel(label); // 如果json数据没有label信息,需要设置一下
graph.addVertex(v);
Vertex result = graph.getVertex(label, "b928a3ff3534bd4b8a2b9c3e742b61d4");
System.out.println(result);
Assert.assertNotNull(result);
}
其中: data/product.json 文件格式如下:
{
"item_brand": "007",
"picture": {
"source": "img10.360buyimg.com",
"urls": [
"http://img10.360buyimg.com/n1/jfs/t2902/43/1061227423/443168/76263cb1/5733df58N2f6bd5d4.jpg",
"http://img10.360buyimg.com/n1/jfs/t2794/85/1052682540/426775/dc9b1676/5733df55N5f92628f.jpg",
"http://img10.360buyimg.com/n1/jfs/t2731/73/1074135671/532784/ed1aceb8/5733df5bN8d402f50.jpg",
"http://img10.360buyimg.com/n1/jfs/t2755/61/1076813373/122635/23d1892a/5733df5eN79234cbe.jpg",
"http://img10.360buyimg.com/n1/jfs/t2707/66/1060021187/261911/6e783e98/5733df52Ne768f5b5.jpg"
]
},
"self_flag": false,
"tag": [
{
"name": "xxxl",
"weight": 1
},
{
"name": "兰精",
"weight": 0.9697308097699757
},
{
"name": "莫代尔",
"weight": 0.8431306441996375
},
{
"name": "男士健康",
"weight": 0.6934955784218877
},
{
"name": "顺滑",
"weight": 0.6630706005804711
},
{
"name": "男士",
"weight": 0.4484346272074258
},
{
"name": "内裤",
"weight": 2
},
{
"name": "短裤",
"weight": 2
},
{
"name": "面料",
"weight": 2
}
],
"brand_for_show": "007",
"key": "b928a3ff3534bd4b8a2b9c3e742b61d4",
"entity_type": "Product",
"item_name": "007男士健康内裤精选兰精莫代尔面料内裤男 舒适顺滑四角短裤头 蓝色 XXXL",
"url_alias": "http://item.jd.com/10345601895.html",
"comments": [],
"third_category": "男式内裤",
"source": [
"jd.com"
],
"status": true,
"hot_comment": [],
"same_product_id": "88fdc791d0d5aa7bee9e4441d4992864",
"item_attribute": [
{
"name": "品牌",
"value": "007"
},
{
"name": "商品名称",
"value": "007男士健康内裤精选兰精莫代尔面料内裤男 舒适顺滑四角短裤头 蓝色 XXXL"
},
{
"name": "商品编号",
"value": "10345601895"
},
{
"name": "店铺",
"value": "龙威内衣专营店"
},
{
"name": "商品毛重",
"value": "50.00g"
},
{
"name": "商品产地",
"value": "中国大陆"
},
{
"name": "货号",
"value": "WL006"
},
{
"name": "腰型",
"value": "低腰"
},
{
"name": "组合规格",
"value": "单条装"
},
{
"name": "类型",
"value": "男士内裤"
},
{
"name": "面料材质",
"value": "莫代尔"
},
{
"name": "颜色",
"value": "蓝色系"
},
{
"name": "花型",
"value": "字母"
},
{
"name": "功能",
"value": "无痕,运动"
},
{
"name": "款式",
"value": "平角裤"
},
{
"name": "尺码",
"value": "L,XL,XXL,XXXL"
}
],
"crawl_time": 1471777010,
"good_comments_rate": 1,
"mypos": [
"服饰内衣",
"内衣",
"男式内裤",
"007"
],
"name": "007男士健康内裤精选兰精莫代尔面料内裤男 舒适顺滑四角短裤头 蓝色 XXXL",
"shelves": 0,
"url": "http://item.jd.com/10345601895.html",
"has_stock": 0,
"comments_count": 0
}
3、Query
/**
* Test Query the God Family Graph
*
* @author arganzheng
*
*/
public class AerospikeGraphQueryTest {
/*
* *****************************************************
*
* Testcase Setup and Teardown
*
* *****************************************************
*/
public static boolean init = false;
Graph graph = null;
@Before
public void setUp() {
// create graph
graph = new AerospikeGraph("test", true);
// drop data first
graph.dropData();
// drop index also
graph.dropIndex();
// init test data
buildTestGraph();
}
public void buildTestGraph() {
String label = "Person";
/** create index **/
// create Index for name -- test equality index
Index idxNameFirst = graph.createIndex(label, "name", IndexType.STRING);
System.out.println("create index " + idxNameFirst);
// create Index for age -- test range index
Index idxAge = graph.createIndex(label, "age", IndexType.NUMERIC);
System.out.println("create index " + idxAge);
// create Index for address/city -- test nested index
Index idxAddressCity = graph.createIndex(label, "address/city", IndexType.STRING);
System.out.println("create index " + idxAddressCity);
// create Index for tags -- test array index
String tagsPath = "tags";
IndexType tagsIndexType = IndexType.STRING;
Index idxTags = graph.createArrayIndex(label, tagsPath, tagsIndexType);
System.out.println("create index " + idxTags);
/** add vertex 1 **/
Vertex v1 = new Vertex("Person", "1");
// add name property
v1.addProperty("name", "argan");
// add age property
v1.addProperty("age", 31);
// add address
Map<String, String> address = new HashMap<>();
address.put("province", "GD");
address.put("city", "ShenZhen");
v1.addProperty("address", address);
// add tags property
List<String> tags = Arrays.asList("smart", "handson", "rich");
v1.addProperty("tags", tags);
/** add vertex 2 **/
Vertex v2 = new Vertex("Person", "2");
// add name property
v2.addProperty("name", "magi");
// add age property
v2.addProperty("age", 29);
// add address
Map<String, String> address2 = new HashMap<>();
address2.put("province", "GD");
address2.put("city", "ShanTou");
v2.addProperty("address", address2);
// add tags property
List<String> tags2 = Arrays.asList("tall", "rich", "handson");
v2.addProperty("tags", tags2);
Edge e = new Edge("friend", v1, v2);
e.addProperty("since", 2009);
graph.addVertex(v1);
graph.addVertex(v2);
graph.addEdge(e);
}
@After
public void tearDown() {
// drop data first
graph.dropData();
// drop index also
graph.dropIndex();
graph = null;
}
/*
* *****************************************************
*
* Begin Query Test
*
* *****************************************************
*/
@Test
public void testEqualitySearch() {
long startTime = System.currentTimeMillis();
DocumentIterator it = graph.V("Person").has("name", "argan").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
Assert.assertEquals("argan", rec.getProperty("name"));
}
} finally {
it.close();
}
}
@Test
public void testRangeSearch() {
long startTime = System.currentTimeMillis();
// DocumentIterator it = graph.V("Person").has("age", Compare.GREATER_THAN, 30).execute();
DocumentIterator it = graph.V("Person").interval("age", 30, 35).execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
long age = (Long) rec.getProperty("age");
Assert.assertTrue(age >= 30 && age <= 35);
}
} finally {
it.close();
}
}
@Test
public void testArraySearch() {
DocumentIterator it = graph.V("Person").has("tags", Contain.IN, "smart").execute();
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
List<String> tags = (List<String>) rec.getProperty("tags");
Assert.assertTrue(tags.contains("smart"));
}
} finally {
it.close();
}
}
@Test
public void testNestedIndexSearch() throws IOException {
DocumentIterator it = graph.V("Person").has("address/city", "ShenZhen").execute();
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
Assert.assertEquals("ShenZhen", rec.getProperty("address/city"));
}
} finally {
it.close();
}
}
@Test
public void testMultiIndexSearch() {
/** add another vertex for test **/
Vertex v = new Vertex("Person", "3");
// add name property
v.addProperty("name", "jenny");
// add age property
v.addProperty("age", 26);
// add address
Map<String, String> address = new HashMap<>();
address.put("province", "ZJ");
address.put("city", "HangZhou");
v.addProperty("address", address);
// add tags property
List<String> tags = Arrays.asList("white", "rich", "beautiful");
v.addProperty("tags", tags);
graph.addVertex(v);
DocumentIterator it =
graph.V("Person").has("tags", Contain.IN, "rich").interval("age", 20, 30).orderBy("age", Order.DESC)
.vertices();
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
List<String> tags2 = (List<String>) rec.getProperty("tags");
Assert.assertTrue(tags2.contains("rich"));
long age = (Long) rec.getProperty("age");
Assert.assertTrue(age >= 20 && age <= 30);
}
} finally {
it.close();
}
}
@Test
public void testQueryEdge() throws IOException {
DocumentIterator it = graph.E("friend").edges();
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
}
} finally {
it.close();
}
}
@Test
public void testQuery() throws IOException {
DocumentIterator it = graph.V("Person").has("name", "argan").out("friend").interval("age", 25, 35).execute();
try {
while (it.hasNext()) {
Document rec = it.next();
System.out.println(rec);
Assert.assertEquals("magi", rec.getProperty("name"));
}
} finally {
it.close();
}
}
}
4、Traversal
@Test
public void testTraversal() {
/** find out who is god's father **/
System.out.println("-- 1: find out who is god's father");
long startTime = System.currentTimeMillis();
// DocumentIterator it1 = graph.V("god").outE("father").outV().execute();
DocumentIterator it1 = graph.V("god").out("father").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it1.hasNext()) {
Document rec = it1.next();
Assert.assertTrue(rec.getKey().equals("saturn"));
System.out.println(rec);
}
} finally {
it1.close();
}
}
@Test
public void testTraversal2() {
/** find out who's father is god **/
System.out.println("-- 2: find out who's father is god");
long startTime = System.currentTimeMillis();
DocumentIterator it2 = graph.V("god").in("father").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it2.hasNext()) {
Document rec = it2.next();
Assert.assertTrue(rec.getKey().equals("hercules"));
System.out.println(rec);
}
} finally {
it2.close();
}
}
@Test
public void testTraversal3() {
/** find out who grandfather is titan. **/
System.out.println("-- 3: find out who grandfather is titan.");
long startTime = System.currentTimeMillis();
DocumentIterator it3 = graph.V("titan").in("father").in("father").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it3.hasNext()) {
Document rec = it3.next();
Assert.assertTrue(rec.getKey().equals("hercules"));
System.out.println(rec);
}
} finally {
it3.close();
}
}
@Test
public void testTraversal4() {
/** find out who is battled with demigod for more than 1 years **/
System.out.println("-- 4: find out who is battled with demigod for more than 1 years");
long startTime = System.currentTimeMillis();
DocumentIterator it4 = graph.V("demigod").outE("battled").has("time", Compare.GREATER_THAN, 1).outV().execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
List<String> battleds = Arrays.asList("hydra", "cerberus");
try {
while (it4.hasNext()) {
Document rec = it4.next();
Assert.assertTrue(battleds.contains(rec.getKey()));
System.out.println(rec);
}
} finally {
it4.close();
}
}
@Test
public void testTraversal5() {
/** find out who are pluto's cohabitants? **/
System.out.println("-- 5: find out who are pluto's cohabitants?");
long startTime = System.currentTimeMillis();
// DocumentIterator it5 = graph.V("god").has("name", "pluto").out("lives").in("lives").execute();
// pluto can't be his own cohabitant
DocumentIterator it5 =
graph.V("god").has("name", "pluto").out("lives").in("lives").hasNot("name", "pluto").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
try {
while (it5.hasNext()) {
Document rec = it5.next();
Assert.assertTrue(rec.getKey().equals("cerberus"));
System.out.println(rec);
}
} finally {
it5.close();
}
}
@Test
public void testTraversal6() {
/** where do pluto's brothers live? **/
System.out.println("-- 6: where do pluto's brothers live?");
long startTime = System.currentTimeMillis();
DocumentIterator it6 = graph.V("god").has("name", "pluto").out("brother").out("lives").execute();
System.out.println("queryTime: " + (System.currentTimeMillis() - startTime));
List<String> lives = Arrays.asList("sky", "sea");
try {
while (it6.hasNext()) {
Document rec = it6.next();
Assert.assertTrue(lives.contains(rec.getKey()));
System.out.println(rec);
}
} finally {
it6.close();
}
}
说明
- 顶点和边的更新、删除比较简单,这里就不展示了。
Features
- 图模型
- Label Property Graph Model – 一期
- Schema-less – 一期
- Index-based – 一期
- Somehow document-oriented (seamless with JSON) – 一期
- 允许不指定label? – 二期
- 索引
- 精确匹配 (Match Index) – 一期
- 范围查询 (Range Index) – 一期
- 嵌套属性索引 (Nested Property Index) – 一期
- 数组索引 (Array Index) – 一期
- Geo查询 (Geo Index) – 二期
- 全文检索 (Fulltext Index) – 三期
- 多查询条件索引优化 (Index/Query Optimization) – 二期
- 接口
- 图接口 – 一期
- createGraph: 由于Aerospike目前不支持动态创建namespace,所以先不支持 – 取决于Aerospike的新版发布时间
- loadGraph – 一期
- loadData: 批量数据导入 – 二期
- dropData – 一期
- deleteGraph: 由于Aerospike目前不支持动态删除namespace,所以先不支持 – 取决于Aerospike的新版发布时间
- 索引接口
- createIndex – 一期
- dropIndex – 一期
- reIndex – 一期
- 顶点接口
- addVertex – 一期
- updateVertex – 一期
- deleteVertex: 需要删除相应的边关系 // TODO – 一期
- queryVertex – 一期
- 边接口
- addEdge – 一期
- updateEdge – 一期
- deleteEdge – 一期
- queryEdge – 一期
- 图接口 – 一期
- 图遍历
- java SDK支持图遍历 – 一期
- 排序(orderBy)、分页(limit)和选取字段(values)– 一期
- Gremlin语法解析 – 二期或者三期
- Python SDK – 二期或者三期
- 聚合函数 (agregations: count, max, min, sum, group by, etc.) – 三期或者四期
- 平台化 – 四期
- 用户权限控制
- 鉴权 & 授权
- 粒度:属性级别?
- 在线申请
- 提供类似于Cayley的在线查询和 visualize 图结果展示
- 支持用户自定义函数(UDF, Server Side script)
- 提供一个Shell或者WebUI监控 & 管理界面
- 系统监控(memory,disk,cpu…)
- 集群管理(cluster)
- 垂类管理(namespace or database)
- 文档管理(CRUD)
- 日志查看 & 监控
- 用户自定义函数管理
- show process功能
- 用户权限控制
说明
由于Aerospike自身的一些局限性,有些功能需要修改Aerospike源码才能支持,包括:
- 动态namespace管理
- namespace限制(主要是一个namespace下只能有256个二级索引)
- bin name长度限制(<= 14 Chars)
- 基于Secondary Index的Query不支持逻辑操作(AND,OR,NOT),只支持单属性查询
- 没有内建的聚合函数(Aggregations: count, max, min, sum, group by, etc.),通过UDFs可以支持(queryAggregate),但是使用方式不友好,效率也不高。
- Query不支持分页(no cursor or pagination..)
- Query不支持排序(no order by..)
- 只支持精确匹配和范围查询,不支持全文检索
- 只支持batch read,不支持batch writes..
- 如果where条件没有相应的索引就会报错,而不是走全表扫描
- 如果没有指定set name,不是对整个namespace进行检索,而是对没有指定set name的数据进行检索。
- Fast Restart
- 图切割优化