Sorting and Relevance
像MySQL这样的数据库,查询结果如果没有order by,那么默认就是按照主键排序的。对于大部分业务场景来说,排序往往取决于某个/些字段的值,但是对于搜索引擎来说,排序却往往跟相关性有关系。那么ES中相关性是什么,又是怎么计算的呢?
Scoring by Relevance
ES默认对结果按照相关性降序排序(By default, results are returned in descending order of relevance.)。
相关性在ES中以_score变量表示,是一个浮点数,默认值是1。那么_score是怎么计算的呢?不同的查询语句有不同的计算规则。不过基本上相关性指的是query和文档之间的相似程度(how similar the contents of a full-text field are to a full-text query string)。
在搜索引擎中,标准的相似性算法就是非常有名的 TF/IDF (term frequency/inverse document frequence)。它主要考虑如下三个因子:
Term frequency
How often does the term appear in the field? The more often, the more relevant. A field containing five mentions of the same term is more likely to be relevant than a field containing just one mention.
Inverse document frequency
How often does each term appear in the index? The more often, the less relevant. Terms that appear in many documents have a lower weight than more-uncommon terms.
Field-length norm
How long is the field? The longer it is, the less likely it is that words in the field will be relevant. A term appearing in a short title field carries more weight than the same term appearing in a long content field.
Individual queries may combine the TF/IDF score with other factors such as the term proximity in phrase queries, or term similarity in fuzzy queries.
说明:这个很容易理解,其实频率跟文本长度肯定是有关系的,同样出现一次,但是A文档有100个词,而B文档有1000个词,肯定是A文档的出现频率更大一些。相关性也更高一些。
TIPS 使用explain查看ES的执行过程
类似于MySQL,ES也提供了explain语句,可以查看某个语句的详细执行过程。
GET /_search?explain
{
"query" : { "match" : { "tweet" : "honeymoon" }}
}
产生类似的结果:
{
"_index" : "us",
"_type" : "tweet",
"_id" : "12",
"_score" : 0.076713204,
"_source" : { ... trimmed ... },
"_shard" : 1, // 1、term and document frequencies are calculated per shard
"_node" : "mzIVYCsqSWCG_M_ZffSs9Q", // 1、rather than per index
"_explanation": { // 2、Summary of the score calculation for honeymoon
"description": "weight(tweet:honeymoon in 0)
[PerFieldSimilarity], result of:",
"value": 0.076713204,
"details": [
{
"description": "fieldWeight in 0, product of:",
"value": 0.076713204,
"details": [
{
"description": "tf(freq=1.0), with freq of:", // 3、Term frequency
"value": 1,
"details": [
{
"description": "termFreq=1.0",
"value": 1
}
]
},
{
"description": "idf(docFreq=1, maxDocs=1)", // 4、Inverse document frequency
"value": 0.30685282
},
{
"description": "fieldNorm(doc=0)", // 5、Field-length norm
"value": 0.25,
}
]
}
]
}
}
说明
1、It adds information about the shard and the node that the document came from, which is useful to know because term and document frequencies are calculated per shard, rather than per index。
2、The first part is the summary of the calculation. It tells us that it has calculated the weight—the TF/IDF—of the term honeymoon in the field tweet, for document 0. (This is an internal document ID and, for our purposes, can be ignored.)
It then provides details of how the weight was calculated:
3、Term frequency: How many times did the term honeymoon appear in the tweet field in this document?
4、Inverse document frequency: How many times did the term honeymoon appear in the tweet field of all documents in the index?
5、Field-length norm: How long is the tweet field in this document? The longer the field, the smaller this number.
Theory Behind Relevance Scoring
Lucene (and thus Elasticsearch) uses the Boolean model to find matching documents, and a formula called the practical scoring function to calculate relevance. This formula borrows concepts from term frequency/inverse document frequency and the vector space model but adds more-modern features like a coordination factor, field length normalization, and term or query clause boosting.
这句话的信息量很大。它高度概括了ES使用的检索和评分模型。大概是这个步骤:
1、检索阶段(Searching/Filtering)
这个跟传统的关系型数据库检索是类似的。只是在搜索引擎使用的索引结构是倒排索引。上面提到的 Boolean Model 其实就是逻辑/集合运算,比如 AND, OR, NOT,因为查询语句往往是多条件组合的,特别是全文检索,一个query其实会被切成多个term进行检索。例如下面的这个查询:
GET /my_index/doc/_search
{
"query": {
"match": {
"text": "quick fox"
}
}
}
ES内部会将其改写成如下bool查询:
GET /my_index/doc/_search
{
"query": {
"bool": {
"should": [
{"term": { "text": "quick" }},
{"term": { "text": "fox" }}
]
}
}
}
ES的 bool query 实现了 Boolean model, 因此,上面的例子中只会得到含有 quick OR fox 的文档。
具体可以参考这个资料,非常通俗易懂: Lecture 1: Introduction and the Boolean Model
2、排序阶段(Ranking/Scoring)
这个阶段的主要目标是对前面匹配的文档进行相关性排序。相关性计算模型就是我们前面提到的 TF/IDF。
首先对每个匹配文档计算下面三个因子:
- Term frequency: tf(t in d) = √frequency
- Inverse document frequency: idf(t) = 1 + log ( numDocs / (docFreq + 1))
- Field-length norm: norm(d) = 1 / √numTerms
然后将这个三个因子合并计算一个总评分:
weight(t, d) = tf(t in d) * idf(t)² * t.getBoost() * norm(t,d)
vector space model
前面检索阶段也说过了,查询语句往往是多个term的,TF/IDF针对的是每一个term,所以我们还需要一种方式把这些term的权重进行加权,得到一个综合评分。这就是 verctor space model 的作用。
它的思想很简单,就是把query和匹配的document向量化。而向量化的方法也非常简单,对于query,就是每个term的score。
假设有个 query = “happy hippopotamus.”。假设 term “happy”的权重为2,”hippopotamus”的权重是5。那么我们可以把这个query向量化为:query = [2,5]。
假设有三个匹配的文档:
- I am happy in summer.
- After Christmas I’m a hippopotamus.
- The happy hippopotamus helped Harry.
那么也可以依次向量化为如下向量:
- Document 1: (happy,____) => [2,0]
- Document 2: ( ___ ,hippopotamus) => [0,5]
- Document 3: (happy,hippopotamus) => [2,5]
向量的好处就是它是可以比较的(The nice thing about vectors is that they can be compared.),通过计算query vector和document vector之间的距离(例如它们之间的夹角),我们可以得到最匹配的向量。这个例子很明显,文档3是最匹配的。
ES最终把TF/IDF和VSM 合并成一个计算公式(practical scoring function ):
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
NOTES && ITPS
1、When we refer to documents in the preceding formulae, we are actually talking about a field within a document. Each field has its own inverted index and thus, for TF/IDF purposes, the value of the field is the value of the document.
2、While TF/IDF is the default way of calculating term weights for the vector space model, it is not the only way. Other models like Okapi-BM25 exist and are available in Elasticsearch. TF/IDF is the default because it is a simple, efficient algorithm that produces high-quality search results and has stood the test of time.
3、Note that term frequency, inverse document frequency, and field-length normalization are stored for each document at index time. These are used to determine the weight of a term in a document.
4、You can read more about how to compare two vectors by using cosine similarity.
Searching and Sorting
通过上面的讨论我们知道相关性的定义和在ES的表示,也知道了ES是怎样计算相关性的。那么ES是怎么排序的呢?
我们知道ES(Lucene)主要是依靠倒排索引(Inverted Index)实现快速的检索。倒排索引的数据结构大概如下:
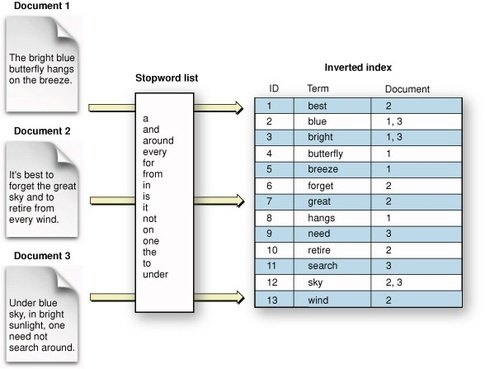
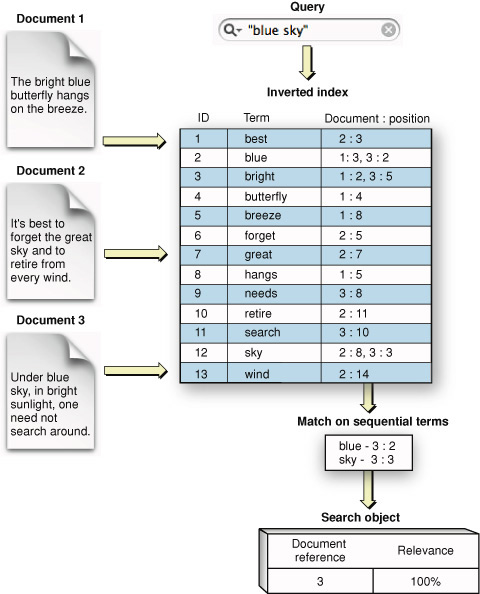
假设我们需要按照某个字段排序,那么DB需要获取每一个匹配文档的那个字段的值。但是倒排索引只能给我们一大堆的docId,并没有排序字段的值。也就是说为了排序我们还需要正排的信息。如果能够把这个排序字段的值也“附加”在倒排索引中,那么可以省去这个获取正排信息的开销。
这个在搜索引擎也有通用的解决方案,就是 Doc Value。
This “uninverted” structure is often called a “column-store” in other systems. Essentially, it stores all the values for a single field together in a single column of data, which makes it very efficient for operations like sorting.
In Elasticsearch, this column-store is known as doc values, and is enabled by default. Doc values are created at index-time: when a field is indexed, Elasticsearch adds the tokens to the inverted index for search. But it also extracts the terms and adds them to the columnar doc values.
Doc Value在ES中有很多使用场景:
- Sorting on a field
- Aggregations on a field
- Certain filters (for example, geolocation filters)
- Scripts that refer to fields
事实上,Facebook的Unicorn: A System for Searching the Social Graph中的HitData就是这个Doc Value。
Boosting
Index boost
Query boost
Query context and Filter context
As a general rule, filters should be used instead of queries:
- for binary yes/no searches
- for queries on exact values
As a general rule, queries should be used instead of filters:
- for full text search
- where the result depends on a relevance score
Unless you need full text search or scoring, filters are preferred because frequently used filters will be cached automatically by Elasticsearch, to speed up performance. See Elasticsearch: Query and filter context.
参考文章
- Elasticsearch: The Definitive Guide [2.x] » Search in Depth » Controlling Relevance » Theory Behind Relevance Scoring
- Elasticsearch: The Definitive Guide [2.x] » Getting Started » Sorting and Relevance » What Is Relevance?
- Elasticsearch: The Definitive Guide [2.x] » Getting Started » Sorting and Relevance » Doc Values Intro
- How scoring works in Elasticsearch
- Optimizing Search Results in Elasticsearch with Scoring and Boosting
- Lecture 1: Introduction and the Boolean Model